
A Project Is Not a Bundle of Tasks
Current AIs struggle to create a whole that exceeds the sum of its parts


Today, AIs can do some things. Eventually, they may be able to do everything. Forecasts generally project forward from what AI can do today, estimating how long it will take to fill in the gaps.
We often underestimate the size of those gaps. Some of this is just “out of sight, out of mind” (or, if you prefer, “availability bias”) – it’s easier to notice the things AIs are doing than the things they aren’t. But also, AIs have important gaps in fuzzy high-level skills that we don’t have great vocabulary for. These skills are applied diffusely across our workday instead of showing up as a crisp bullet on a todo list, making it easier to forget they exist.
In today’s post, I’m going to discuss some of the capabilities that AIs will need to acquire in order to progress from carrying out tasks to automating entire projects and jobs. I’ll also argue against some specific ideas that are sometimes presented in arguments for “short timelines” (AGI arriving within the next few years).
I’ll mostly be talking about software engineering. Automated coding is central to many scenarios of rapid AI progress, and it’s the domain I know best. But the principles I’m going to discuss apply to many fields.
Projects Don’t Decompose Into Tasks
We often analyze AI’s aptitude for a job by enumerating the tasks involved in that job. However, the whole is more than the sum of its parts. Breaking up a job (or a large project) into tasks is a useful mental scaffold, but it’s also an oversimplified way of thinking about things. The boundaries between tasks are not clean; information bleeds across. To quote from what I wrote in entry 24 of 35 Thoughts About AGI and 1 About GPT-5:
...A large project does not neatly decompose into tidy subprojects.
For instance, when I tackle a subtask during a large software project, the result is not just that a certain chunk of the code gets written. I come out with a slightly deeper understanding of the problem. I may have learned new things about the existing codebase. I may have hit upon a handy trick for testing the kinds of operations that this code performs, or had an insight about the data being processed. I may have gotten some little nudge that will eventually accumulate with 20 other nudges across other portions of the project, eventually leading me to rethink my entire approach. If the subtask is assigned to a separate agent, whose memories are discarded as soon as the subtask is complete, none of that learning can take place.
If we think of a job as just a collection of tasks, we miss something important. A recent article, AI isn’t replacing radiologists, provides a nice illustration of this in another domain: a radiologist doesn’t just analyze images, they actually spend more time “on other activities, like talking to patients and fellow clinicians”.
If You Can Plan a Month, Can You Plan a Year?
To make concrete forecasts about the future, we tend to look for a graph that plots the thing we’re interested in, and extend the line. When discussing the future of AI, people often turn to this graph (I wrote an entire post about it):
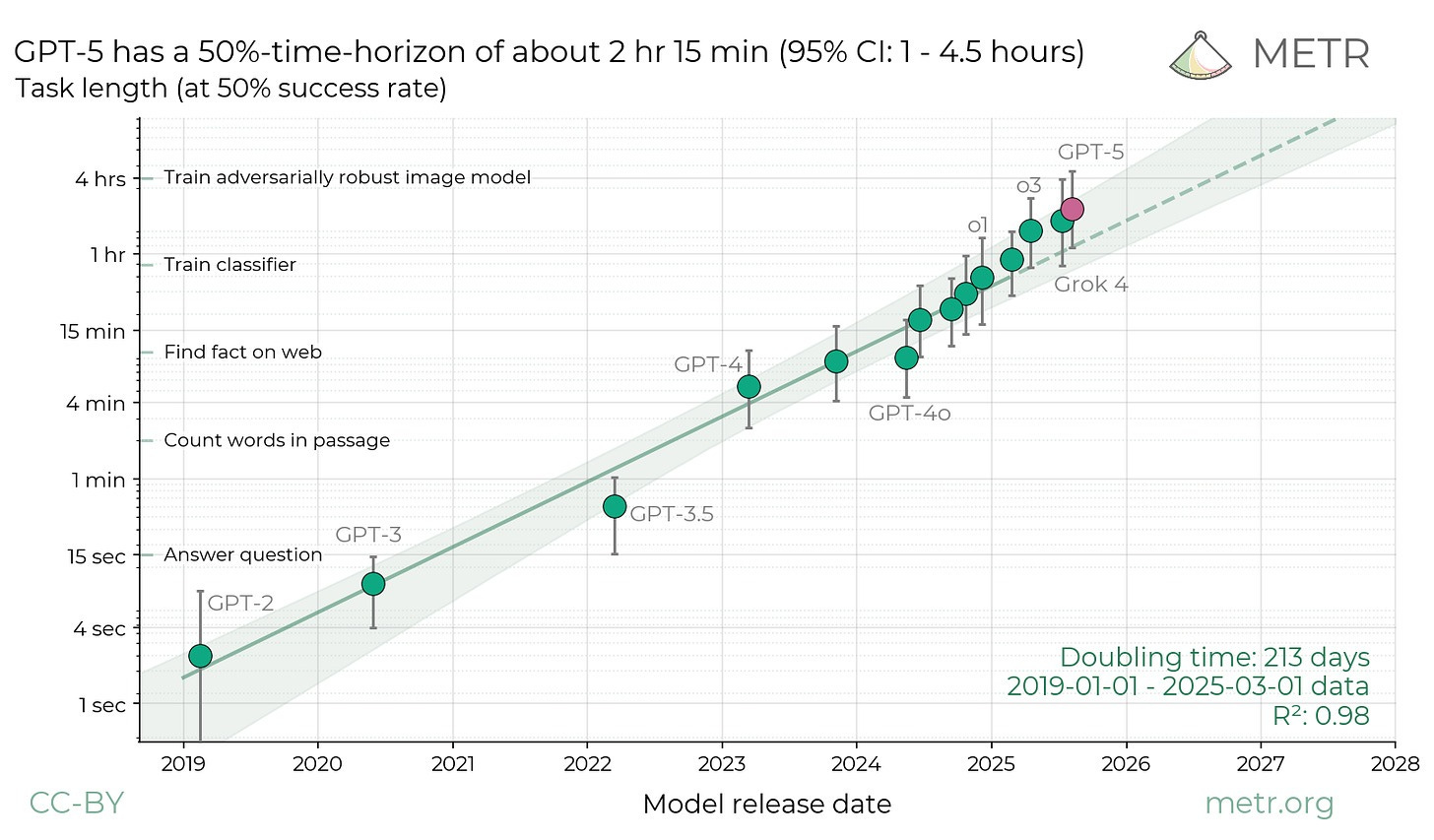
Roughly speaking, the vertical axis shows the size of software engineering tasks an AI can complete on its own1. One argument goes that AIs will be able to fully automate software engineering when they can independently handle large projects; people define “large” as anything from 1 month to 100 person-years or more. This seems pretty intuitive, and it has the nice property that it converts “fully automated software engineering” from an abstract concept into a point on this handy graph – a graph that exhibits a reassuringly predictable trend.
However, there are questions as to the nature of that trend. It appears to bend upwards near the end. Is that just a blip, or does it indicate that AI capabilities are accelerating? One argument is that as AIs acquire the skills to carry out intermediate projects, those same skills will enable them to carry out large projects. This would imply that while it may have taken a lot of R&D for AIs to progress from 1-minute tasks to 2-minute tasks, or 1 hour to 2 hours, it will be comparatively easy to advance from 1 week to 2 weeks. And an AI that can carry out 1-month tasks may be ready to carry out projects of any size. Here’s one expression of this idea:
...it seems like once you have the agency skills to make consistent progress on very hard tasks (e.g. via task decomposition, noticing mistakes and error correcting, planning), you can move through the increased horizons very quickly because you [are] solving tasks by essentially applying the same skills over and over2.
I think this discounts the complexity of managing a large project. I’ll illustrate this by talking about two software engineering projects in which I played a leading role, a 1-person-year project and a (roughly) 100-person-year project.
Launching Google Docs: 1 Person-Year
In 2005, my friend Sam Schillace had the idea that would eventually become Google Docs. With another friend (Claudia Carpenter), we spent about 4 months building an alpha version, which we released under the name “Writely”.
Those 4 months didn’t involve much big-picture thinking. I hacked together a server to store documents, Claudia designed and coded the toolbar and other UI elements, Sam built the web page that wired it all together. Problems arose; we fixed them. Everything was done seat-of-the-pants, we addressed problems as they came up, a lot of cans were kicked down the road. This is not to say that the work was easy: I had to come up with a way to synchronize changes when multiple people were editing the same document; Sam and Claudia had to wrestle with cutting-edge browser features that were often buggy and poorly documented. But it was all kind of “small ball”: it wasn’t hard to keep the entire system in our heads, and we didn’t worry about the long-term consequences of any decisions we were making.
Building Scalyr: 100 Person-Years
In 2011, I founded another startup, Scalyr. A team that grew to dozens of engineers spent 10 years building a system that could analyze vast quantities of log data to troubleshoot problems in complex web applications.
This was an entirely different kettle of fish from Writely, and my 2005 self would never have pulled it off. I relied on lessons I’d learned by fumbling my way through large-scale projects at Google (after Writely was acquired), as well as skills acquired on the job at Scalyr. Building Scalyr involved things such as:
Finding systematic solutions to operational issues. Scalyr was a complex application, relying on coordinated activity across thousands of servers. Fixing problems one-by-one would have been unsustainable. To keep things on an even keel, it was necessary to identify patterns of behavior, and find a single change that would eliminate an entire category of problems at once. Furthermore, each change had to be something that could be accomplished with minimal effort or disruption. To play my part, I had to lean on years of general experience in sniffing out software bugs, further years of specific experience with the system we built at Scalyr (the sort of “continuous learning” that current AIs don’t do), and hard-won judgement as to which changes would be safe and tractable.
Strategic planning and execution. Midway through building the company, we encountered major setbacks – our largest customer abruptly departed, and we were struggling to land new clients. We needed to find a new course. After months of discussion, we decided that our core competitive advantage lay in something that had been a minor detail in our original product conference; processing large volumes of data at high speed and low cost. We then planned and executed a multi-year effort to expand on that advantage. A few skills required here: figuring out which parts of our complex server architecture needed to change; breaking those changes down into incremental steps that wouldn’t be too complex for the team to handle; identifying the critical assumptions in our plan, and finding ways to validate those assumptions early; spotting problems early and correcting them with minimal disruption to the plan.
Developing techniques to diagnose subtle performance issues. Our performance goals required that in a fraction of a second, a task could be distributed across thousands of servers, carried out, and the results consolidated – efficiently flowing alongside other tasks. Seemingly minor changes to the code could disrupt the smooth flow and destroy our competitive advantage. To solve such problems, we had to find ways to record enough data to allow us to analyze task flow, without recording so much data as to be unmanageable. This required high-level judgement in identifying the critical hinge points in the system, and only collecting data at those critical points.
(I also shared some thoughts about the different skills involved in small vs. large projects in 35 Thoughts About AGI and 1 About GPT-5 – entries 19 through 25.)
What Got AI Here Won’t Get It There
As Claude puts it:
“What Got You Here Won’t Get You There” is a concept popularized by executive coach Marshall Goldsmith in his book of the same name. The core idea is that the skills, habits, and behaviors that lead to success at one level often become obstacles at the next level.
My personal experience as a software engineer supports this idea. The “agency skills” that were sufficient banging out the original Writely prototype would have been utterly inadequate for managing the first 100 person-years of Scalyr, and indeed would often have gotten in the way. I expect that this generalizes, and the level of skill at task decomposition, error correction, and planning that will allow an AI to navigate 1-year projects will not suffice for larger projects.
Nor is the difference just about generic “agency skills”. Acting as a senior engineer at Scalyr required a lot of very specific, advanced domain skills that only come after years of experience. For instance, learning to look at a report of the last month’s operational issues and spot a pattern that will allow an entire category of problems to be stamped out through a single change. These sorts of skills are generally not necessary for smaller projects, nor does experience at smaller projects necessarily help develop them. Thus, when AI systems master 1-year projects, I think that larger projects will still challenge them.
Large-Scale Projects Stress Deep Cognitive Skills
Large-scale projects don’t just require project management skills and advanced domain knowledge. They lean on a cluster of cognitive skills that are lacking in current AIs:
Context management. The bigger the project, the more details you need to keep in mind. This is especially true for big-picture planning, but it even applies when working on specific tasks. It’s important to consider the relevant details – which means you need to be able to pick those details out from the larger mass of information that a large project generates (entry 30 of 35 Thoughts).
Continuous learning and adaptability. Seasoned veterans on long-running projects are valuable in part because they have honed bespoke skills specifically adapted to that project. They have become expert at troubleshooting the exact sorts of problems that come up, and they automatically write code that fits with the project’s specific design choices.
Metacognition. On a small project, you just dive in and get it done. On a large project, it’s worth your while to analyze what is and isn’t working, where you (or your team) tend to get stuck, what sorts of techniques work well, and where you need to develop new skills.
Nathan Lambert recently touched on all of this:
The amount of context that you need to keep in your brain to perform well in many LM training contexts is ever increasing. For example, leading post-training pipelines around the launch of ChatGPT looked like two or maybe three well separated training stages. Now there are tons of checkpoints flying around getting merged, sequenced, and chopped apart in part of the final project. Processes that used to be managed by one or two people now have teams coordinating many data and algorithmic efforts that are trying to land in just a few models a year. I’ve personally transitioned from a normal researcher to something like a tech lead who is always trying to predict blockers before they come up (at any point in the post-training process) and get resources to fix them. I bounce in and out of problems to wherever the most risk is.
[emphasis added]
We Won’t Have Automated Software Engineering Until AIs are Leading 100-Person-Year Projects
Impactful software engineering projects are usually large, complicated beasts – if not at first (Writely), then as they grow and mature (Google Docs). Certainly there are complex projects taking place inside the big AI labs. Analysis based on the automation of specific tasks misses the forest for the trees. Software engineering will not be fully automated until AIs can handle projects of the 100-person-year scale (or more). How long until that happens?
It’s impossible to predict with any certainty. But we can take a stab. The graph I presented at the top of this post shows current AI models achieving a 50% success rate at tasks that take about two person-hours. The paper where that graph originated finds that the manageable task size doubles every 7 months. It would take about 16 doublings to get from two person-hours to 100 person-years3; at 7 months per doubling, that puts us around the beginning of 2035. Advancing from a 50% success rate to full competence might take a few more years, putting automated software engineering in the late 2030s. Adjusting for real-world conditions might push the schedule out further.
The same paper finds preliminary evidence that the doubling time might now be shrinking to just 4 months, which (if we discount adjustments for real-world conditions) would imply fully automated software engineering in the early 2030s. That would be startlingly fast in terms of its impact on the world, but considerably slower than some scenarios for AI progress. Those aggressive scenarios generally assume that the rate at which AI climbs the ladder of project scope will continue to accelerate, and/or that the task scope threshold for full automation is far lower than 100 person-years. In this post, I’ve explained why I don’t agree.
These estimates are balanced on the slender reed of a single graph from a single study. We shouldn’t take any of them too seriously. But that graph is the single best tool we currently have for answering a critical question about the likely pace of AI progress. And I think readings of that graph that point toward rapid automation neglect the full complexity of software engineering.
The most likely scenario for faster progress would involve unexpected breakthroughs, either in the design of AI models, or in the way we apply them to the task of large-scale software development (perhaps we will find ways to use AI’s superhuman strengths to better compensate for its weaknesses). Breakthroughs, of course, are hard to predict – and hard to rule out.
Sam Altman recently announced that OpenAI has an internal goal to create “a true automated AI researcher by March of 2028” – just 2.5 years from now. Jakub Pachocki, OpenAI’s chief scientist, made clear this means a “system capable of autonomously delivering on larger research projects.” This seems unambiguously inconsistent with the observed trend of progress in AI capabilities. That doesn’t mean it can’t happen! But it can’t happen without a major breakthrough4.
In the meantime, of course, we will have partial automation; code-authoring tools are already providing value, though the benefits may often be overestimated. There are (disputed) reports that AI tools are already writing 90% of code at one frontier AI developer. If partial automation can drastically improve the productivity of engineering teams, that may have a major impact on AI timelines, not to mention the job market for software engineers, and the tech industry in general. I am also somewhat bearish on drastic effects from partial automation, but that’s a subject for another day.
Thanks to Abi Olvera, Eli Lifland, James Cham, John Hart, Michael Chen, Nate Rush, and Taren Stinebrickner-Kauffman for feedback (and to Abi for the post image).
Actually, the graph shows the size of tasks for which the success rate is 50%. The size of tasks which AIs can reliably carry out is much less. Also note that the measurements are specifically for software engineering-style tasks that can be graded automatically (e.g. “does this code pass tests”, not “is it easy to understand and consistent with style guidelines”), and the time scale is calibrated against human engineers who are not familiar with the specific codebase the task applies to.
From an unpublished draft of a forecast I was asked to review.
Assuming a 2000-hour work year.
It’s certainly possible that we could see one-off examples of an AI system carrying out something that could be characterized as a “research project”, just as Google DeepMind’s AlphaEvolve system has already delivered a scattering of incremental advances in areas relevant to AI, such as matrix multiplication algorithms. But it would be far off-trend to see anything in March 2028 that can independently carry out “larger research projects” at anything like the capability of a human researcher, with any generality, and at anything approaching a competitive cost.
>There are (disputed) reports that AI tools are already writing 90% of code at one frontier AI developer
This may be completely true and in same time lead to zero productivity gains. Very often, it simply means that people, instead of programming in a programming language, start "programming" in prompts.
In my experience, AI writes more than 90 percent of my code when it is simply because almost all the typing is automated by my AI IDE(cursor). But this didn't speed up my work at all, because writing code is a small part of it
My experience doing LLM research is that the average research project is of roughly 3-4 months in duration, and even major projects are rarely >9 months (except well known examples like GPT-4, o1, etc, which are a little longer (but even those are highly decomposable)). In fact, I think AI research as currently practiced by industry labs is *unusually easier to automate* relative to fully automating software engineering.
So overall while I think you could be correct about the SWE trend, I currently think it will be possible to automate medium size research projects by 2028, that a team of 2-3 researchers in an industry lab might be assigned today for 3-6 months. And it's hard to see how the cost would not be competitive given that AI research talent is so scarce.