
Finally, A Way to Measure AI Progress; Everyone's Misreading It
That METR Study Doesn’t Say "AGI in 5 Years"

We all know that AI is improving. But no one knows how quickly.
That might seem like an odd thing to say. Each new model is accompanied by a slew of test scores, showing how much it’s improved on the previous model. The problem is that these numbers don’t give us much perspective, because we keep having to change measurement systems. Almost as soon as a benchmark (a test of AI capabilities) is introduced, it becomes “saturated”, meaning that AIs learn to ace the test. So someone comes up with a more difficult benchmark, whose scores aren’t comparable to the old one. There’s nothing to draw a long-term trend line on.
METR, a nonprofit that evaluates the capabilities of AI systems, recently published a study aimed at addressing this problem: Measuring AI Ability to Complete Long Tasks. They show how to draw a trend line through the last six years of AI progress, and how to project that trend into the future.
The study’s results have been widely misinterpreted as confirmation that AGI (AI capable of replacing most workers, or at least most remote workers) is coming within five years. In actuality, the study doesn’t say much about AGI, except to provide evidence against the most aggressive forecasts.
To explain what the paper does and does not say, I’ll begin by explaining the problem it set out to address.
We’re Gonna Need a Harder Test
Here’s a chart I’ve shown before:
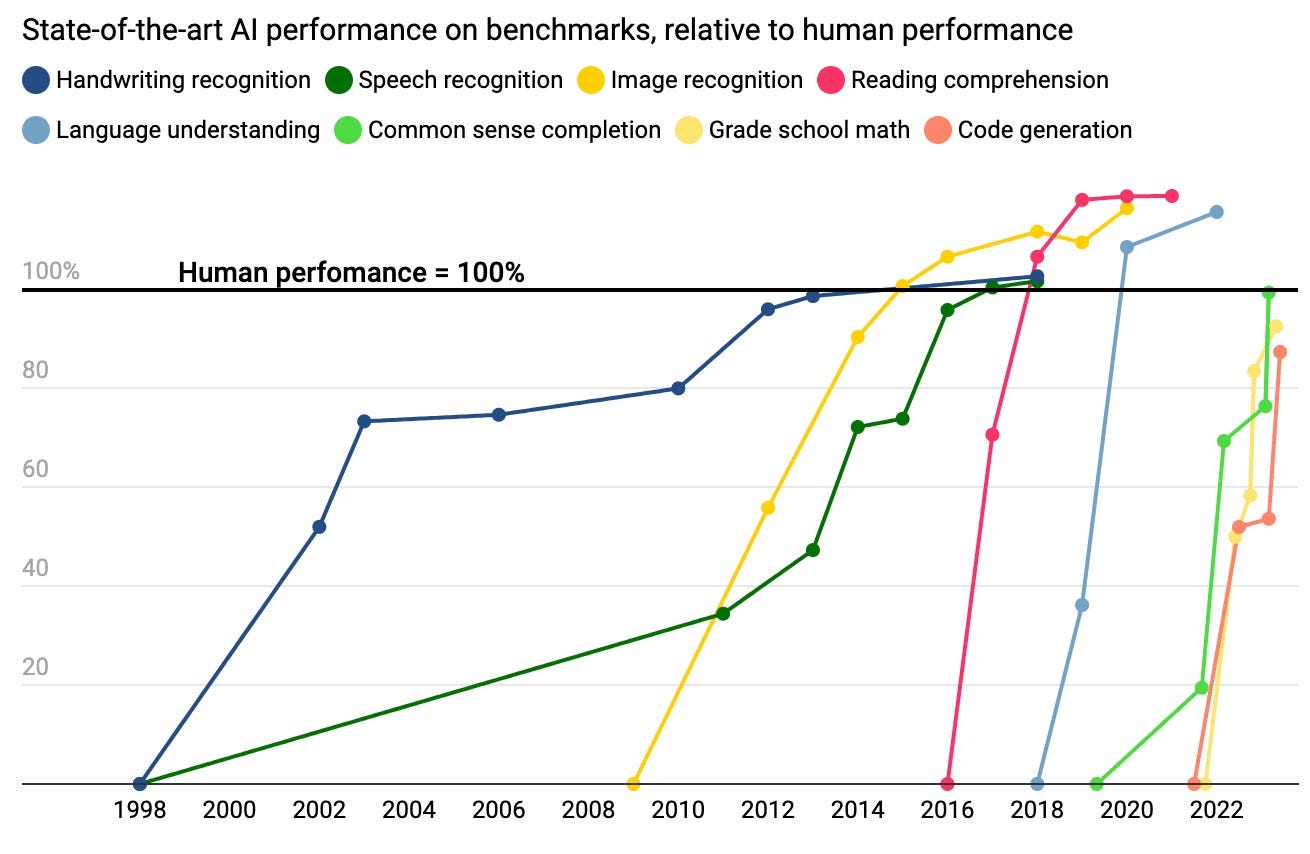
Each line represents AI performance on a particular benchmark. Unsurprisingly, there’s a clear pattern of rapid improvement. But each line is measuring something different; we can’t connect the dots to plot a long-term trend.
For instance, the dark green line shows scores on a speech recognition test. If you’d looked at that plot in 2013, you might have been able to estimate speech recognition scores for 2015. But you’d have had no way of anticipating that reading comprehension (pink line) would start to take off after 2016. Performance on one benchmark doesn’t say much about performance on another.
(This chart provides a reminder that AI test scores are poor indicators of real-world capability. By 2018 language models were exceeding human performance at a benchmark of reading comprehension, but they were still useless for most tasks.)
You can see that in recent years, tests have begun saturating very quickly. As a result, these benchmarks haven’t been much use in forecasting the performance of future AIs. We can’t forecast benchmark scores for the AIs of 2027, let alone 2035, because benchmarks difficult enough to challenge those AIs haven’t been constructed yet.
The METR paper addresses this by allowing us to compare scores across different tests.
Grading AIs on a Consistent Curve
The METR paper creates a single plot showing AI models released over a six-year period, and projects that plot into the future:

The first model shown here, GPT-2, was barely able to fumble its way through a coherent paragraph. The most recent, Claude 3.7 Sonnet, is able to write complex computer programs at a single blow. How did METR measure such disparate capabilities on a single graph?
No one has constructed a benchmark with questions easy enough to register the capabilities of GPT-2 and hard enough to challenge Claude 3.7, so the authors combined three different benchmarks spanning a broad range of difficulty levels. One consists of “66 single-step tasks representing short segments of work by software developers, ranging from 1 second to 30 seconds”, and the questions are quite simple. Another, RE-Bench, is designed so that most human experts can “make progress” on a problem if given a full 8 hours.
To place these very different benchmarks on a common scale, the researchers evaluated the difficulty of each problem by measuring how long it takes a human expert to solve – a task that takes a person one hour is presumed to be harder than a task that takes a minute. This approach has the great benefit of being universal; any task can be placed on the “how long does it take?” scale.
For each model, they then determined the problem size for that model’s success rate is 50%. For instance, “GPT-4 0314” (the green square near the middle of the graph) has a 50% success rate at problems that take people about 5 minutes. Looking at each end of the graph, we see that GPT-2 (released in 2019) had 50% success on tasks that take a person about two seconds, while the latest version of Claude does equally well on tasks that take 50 minutes.
There are a lot of caveats to these figures, which I’ll discuss below. But it’s immediately apparent that capabilities are increasing at a predictable rate, providing perhaps the first rigorous approach for forecasting the rate of AI improvement for real-world tasks. As the paper says [emphasis added]:
If these results generalize to real-world software tasks, extrapolation of this trend predicts that within 5 years, AI systems will be capable of automating many software tasks that currently take humans a month.
This is, as the expression goes, “big if true”. Most people’s jobs don’t require much planning or execution on a time horizon of more than a month! If these results generalize to tasks other than coding, and an AI could do anything a person could do (remotely) in a month, it would be ready to automate much of the economy. Many people are reading the paper as predicting this will happen within five years, but in fact it does not.
How Applicable to the Real World are These Results?
There are several important reasons that the study does not imply a short road to AGI.
It only measures technical and reasoning tasks. The tasks used in the METR paper come from software engineering and related fields, as well as tests of verbal reasoning or simple arithmetic. These are areas where current models are especially proficient. Problem domains that current LLMs struggle with were excluded.
Just because Claude 3.7 can often tackle a 50-minute coding task, doesn’t mean it will be similarly proficient for other kinds of work. For instance, like all current models, it is almost completely incapable of solving visual reasoning tasks from the ARC-AGI-2 test that a person can often manage in a few minutes1. Natalia Coelho posted a nice discussion, noting that “State-of-the-art AI models struggle at some tasks that take humans <10 minutes, while *simultaneously* excelling at some tasks that would take humans several hours or days to solve.” I’ve written before about the jagged nature of AI abilities, and the wide gap between AI benchmark scores and real-world applicability. So even if the paper’s trend line is correct and the AIs of 2030 will be able to undertake tasks that take software engineers a month, they are likely to struggle in other areas.
In fact, not only do current AIs struggle at many real-world tasks, their rate of improvement at those tasks might turn out to be slower as well. We can make an analogy to Wright’s Law – the principle behind Moore’s Law, and also the reason that solar panels, EV batteries, and many other products become cheaper over time. Wright’s Law states that the production cost of manufactured items falls at a predictable rate as production scales up. However, different products have different rates of price decrease; wind turbines fall in price more slowly than transistors or solar panels. By the same token, AI performance on different kinds of work may improve at different rates, with some categories being slower to advance.
The tasks used in this paper are all tidy, isolated projects with clear success criteria, excluding all of the squishy skills I discuss in my recent post If AGI Means Everything People Do... What is it That People Do?. This is typical of AI benchmarks, which almost universally measure things that are easy to measure. For instance, from the description of one of the benchmarks used in this paper (HCAST):
The instructions for each task are designed to be unambiguous, with minimal additional context required to understand the task… [whereas] most tasks performed by human machine learning or software engineers tend to require referencing prior context that may not [be] easy to compactly describe, and [do] not consist of unambiguously specified, modular tasks.
…every task comes with a simple-to-describe, algorithmic scoring function. In many real world-settings, defining such a well-specified scoring function would be difficult if not impossible. All of our tasks involve interfacing with software tools or the internet via a containerized environment. They are also designed to be performed autonomously, and do not require interfacing with humans or other agents.
To their credit, the METR authors note that tasks which arise in real work are often “messy” in a way that distinguishes them from benchmark problems. They developed a rough system for evaluating the “messiness” of a task, and found that their results are fairly consistent across tasks of different levels of messiness. However, none of the measured tasks are very messy. As the paper says:
The mean messiness score amongst HCAST and RE-Bench tasks is 3.2/16. None of these tasks have a messiness score above 8/16. For comparison, a task like ’write a good research paper’ would score between 9/16 and 15/16, depending on the specifics of the task.
Even this may understate the artificial simplicity of the benchmark tasks. Little weight is given to the question of interacting with other people (e.g. collaboration with a co-worker or negotiation with a vendor), and my impression is that few if any of the problems require this. I also don’t believe that any of the problems involve working in an open-ended environment such as the public Internet or a large corporate intranet – for instance, to find relevant context not included in the problem statement. These measurements don’t evaluate AI’s ability to work in a fully realistic environment.
The measurements of human task-completion time do not reflect real-world conditions. The paper measures AI tools against human contractors with relevant coding skills. However, the contractors weren’t familiar with the specific context of each task. They’re in the disoriented situation of a new hire on their first day of work.
Admirably, the authors recognized this issue and performed an experiment to measure the impact. They took a set of tasks which METR engineers had performed in the ordinary course of their work, and asked outside contractors to repeat those tasks – under the same artificial circumstances used in the study. They found that contractors took 5 to 18 times longer to perform the same tasks as METR staff. The contractors they selected were highly skilled, so this is unlikely to be a skill issue. Unsurprisingly, people take much longer to perform a task when they are working in an unfamiliar context. This same handicap applies to the human “baseliners” METR used to evaluate the difficulty of the tasks analyzed in this paper. When the paper says that Claude 3.7 has a 50% success rate at tasks which take a person 50 minutes, that suggests a person familiar with the codebase in question might be able to perform the same task 5-18 times faster, or just 3 to 10 minutes.
It’s a long road from a 50% task success rate to actual mastery. The headline projection in the paper is that in about 5 years, AIs will be able to carry out roughly 50% of software engineering tasks that take humans one month to complete. A 50% score is a good indication of progress, but a tool that can only complete half of the tasks assigned to it is a complement to human engineers, not a replacement. It likely indicates that the model has systematic shortfalls in some important skill areas. Human workers will still be needed for the other 50% of tasks, as well as to check the AI’s work (which, for some kinds of work, may be difficult).
The paper finds that time horizons for an 80% success rate are about five times shorter, e.g. Claude 3.7 would likely have an 80% success rate for tasks that take about 10 minutes instead of 50 minutes. Even an 80% success rate is far from full mastery, but there isn’t enough data yet to analyze the timeline for higher success rates.
Many readers have glossed over these factors, leading them to overblown conclusions regarding the future of AI.
What the METR Study Tells Us About AGI Timelines
This is a nuanced piece of work, but nuance is often lost as ideas bounce around the Internet. For instance, an article in Nature, AI could soon tackle projects that take humans weeks, says:
At the 2019-2024 rate of progress, METR suggests that AI models will be able to handle tasks that take humans about a month at 50% reliability by 2029, possibly sooner.
One month of dedicated human expertise, the paper notes, can be enough to start a new company or make scientific discoveries, for instance.
The words “software engineering” do not appear in this passage. A casual reader might easily come away thinking that AI will be able to perform virtually any cognitive task by 2029, and many people do seem to have reached that conclusion. However, a careful reading points in a different direction. The paper’s 2029 estimate is for tasks that current models are specifically designed to excel at (software development), that have unrealistically simple and clear specifications, measuring against human workers in their first day on the job. Even then the AIs are only projected to be able to perform half of the tasks.
If we adjust for the 5-18x speed improvement measured for experienced workers, and target an 80% task success rate, that pushes the timeline out by over three years2. However, an 80% success rate still indicates substantial gaps within software engineering tasks, and then we need to account for realistically messy tasks3 and consider tasks outside of software engineering. This might add multiple years to the timeline, pushing us out to at least ten years for an AI that is fully human-level at a broad range of tasks, and possibly much longer, depending on how long it takes to go from 80% of tasks to 100%4 and from software engineering to broader competence.
I was originally planning to end this post by saying that this paper is strong evidence that “AGI” (by any strong definition) almost certainly could not possibly arrive in the next five years, because the trendline puts the much weaker threshold of “50% of artificially tidy software engineering tasks” that far out. However, it turns out there’s more to the story.
Recent Models Have Been Ahead of the Curve
While the paper’s primary finding is that AI task time horizons have been doubling every 7 months over the last six years, it notes that progress on this measurement may be accelerating:
However, the trend in 2024 and early 2025 may be faster, with o1 and Claude 3.7 Sonnet lying above the long-run trend. Though the gap is difficult to distinguish from noise, it is robust to methodological ablations like using continuous scoring (Appendix D).
This was based on just a handful of data points, and so could have just been a blip – “difficult to distinguish from noise”. But just last week, METR released a preliminary evaluation of two new models from OpenAI, o3 and o4-mini. The results add support to the idea that AI task time horizons are accelerating. Thomas Kwa, one of authors of the original paper, writes:
Time horizon of o3 is ~1.5 hours vs Claude 3.7's 54 minutes, and it's statistically significant that it's above the long-term trend. … My guess is that future model time horizon will double every 3-4 months for well-defined tasks (HCAST, RE-Bench, most automatically scorable tasks) that labs can RL on, while capability on more realistic tasks will follow the long-term 7-month doubling time.
The authors of AI 2027 are also on record as expecting the time for task time horizons to double to be much less than 7 months going forward, pointing to the recent acceleration trend and predicting that use of AI tools in AI R&D will speed things up further. The gods of AI love to draw straight lines on semilog graphs, but perhaps they’ve decided an upward curve would be more amusing in this case. If the upward trend continues, models could reach a 50% success rate on one-month software engineering tasks by 2027.
It’s still an open question what that would mean in practical terms.
We’re Running Out Of Artificial Tasks
It’s unclear whether the recent uptick in progress on the HCAST problem set used in the METR study will continue, and how long it will take to go from a 50% success rate to full mastery of these kinds of encapsulated coding challenges. Maybe it’ll only be a few years before AIs models can tackle any such problem that a person could handle; maybe it’ll be a decade or more. But either way, the practice of evaluating AI models on easily graded, artificially tidy problems is starting to outlive its usefulness.
The big questions going forward are going to be:
How quickly are AIs progressing on real-world problems?
How broad is that progress – is it restricted to specific domains (such as coding), or is it expanding to cover the broad range of squishy things that people do every day?
(As I was preparing to publish this, Helen Toner released a great post exploring these questions.)
The METR paper is a valuable step forward in analyzing AI progress over time. But it’s only a starting point.
Thanks to David Rein, Rachel Weinberg, Taren Stinebrickner-Kauffman, and Thomas Kwa.
The creators of the ARC-AGI-2 problem set state that no current AI model is able to solve more than a few percent of these puzzles. I tried 10 problems, and was able to figure most of them out in under a minute (even if it took a few more minutes of clicking around to fill in the answer grid using the clumsy interface provided). I will note however that I ran out of patience before figuring out 2 of the 10 problems.
Using the paper’s estimate that a model which can achieve 50% success at tasks which take T seconds can achieve 80% for tasks which take T/5 seconds, and estimating a 10x time penalty for human workers lacking job context (middle of the 5x – 18x range) combines to yield a 50x difference in task length. If AIs can double their task horizon every 7 months, that works out to 5.6 doublings, or 40 months.
The unrealistically simple nature of the benchmark tasks might already be at least partially captured by the 5-18x time penalty I’m applying, as discussed in the previous footnote.
You might ask why I suggest that AIs would need to be able to handle 100% of tasks, when people are of course not 100% reliable, especially when given challenging problems. And indeed, it would be unfair to say that an AI should be 100% reliable before it can be considered “human level”. However, the comparison here is not an individual person, it is humanity collectively – or at least, an individual person plus all of the co-workers and other people they might be able to ask for help. AIs are much more homogenous than people, so “this AI can’t solve this type of problem” is a more serious issue than “this particular person can’t solve this type of problem”.
1. AI labs do a lot of software engineering specifically devoted to making AI
2. AI labs can use their own data about the software engineering for AI to train their AI model
3. Therefore, we can expect AI systems to get much better at AI-software-development *specifically* quite fast
4. Once you have an AI which is good at AI software development, this lets you use that AI to make other AI for different areas faster
5. ...
6. Intelligence explosion
.... And so on. That's the basic idea in the forecast AI-2027. Will it end up being true? Who knows, but something like this seems at least plausible.
Thanks.