
35 Thoughts About AGI and 1 About GPT-5
Such As: How do Teenagers Learn to Drive 10,000x Faster Than Waymo?

Quick reminder that the regular application deadline for The Curve is next Friday, August 22nd! In case you missed it: on October 3-5, in Berkeley, we’ll bring together ~250 folks with a wide range of backgrounds and perspectives for productive discussions on the big, contentious questions in AI. Featuring Jack Clark, Jason Kwon, Randi Weingarten, Dean Ball, Helen Toner, and many more great speakers! If you’d like to join us, fill out this form.

Amidst the unrelenting tumult of AI news, it’s easy to lose track of the bigger picture. Here are some ideas that have been developing quietly in the back of my head, about the path from here to AGI.
I drafted this post a couple of weeks ago. The subsequent launch of GPT-5 didn’t lead me to make any changes. That says something about how uneventful GPT-5 is.
Current AIs aren’t AGI. But I don’t know why.
I mean, I have thoughts. I talk about missing functions like “memory” and “continuous learning”, and possibly “judgement” and “insight”. But these are all debatable; for instance, ChatGPT has a form of memory. The honest answer is: I dunno what’s missing, but something is, because there are a lot of things AI still can’t do. Even if it’s getting harder and harder to articulate exactly what those things are.Prior to GPT-5, ChatGPT users had to tell the chatbot whether to think hard about a problem (by selecting a “reasoning” model like o3), or just give a direct answer. One of the biggest changes in GPT-5 is that the system decides for itself whether a question calls for “thinking hard”. And, according to many reports, it often gets this wrong. In other words, current cutting-edge AIs can solve Ph.D-level math and science problems, but can’t reliably decide which questions deserve thinking about before answering.
(OK, I lied: GPT-5 didn’t lead me to change any of my previously written points, but it did prompt me to add this one.)Often, when embarking on a large software project, I can’t see how it’ll come together. The task may be too complex to wrap my head around, or there may be conflicting requirements that seem difficult to reconcile. Sometimes this eventually leads to an “aha” moment, when I find a clever reframing that changes the problem from confusing and intractable to straightforward and tractable. Other times I just grind away and grind away until there’s nothing left to do.
The latter cases, with no aha moment, are disconcerting. Lacking a specific moment when the difficulty was overcome, I find myself questioning whether I have in fact overcome it. I worry that I’ve missed something important – that I’ve built something in the my workshop that will never fit out the door, or an airplane that’s too heavy to fly. Sometimes this does in fact turn out to be the case; other times everything is fine.
Will the journey from here to AGI feature “aha” moments? Or will it be a long slow grind, and when we get to the end and look back to see what the key insights were, we won’t be able to find any?Back in the 80s and 90s, I used to attend SIGGRAPH, the annual computer graphics conference. The highlight of the week was always the film show, a two-hour showcase demonstrating the latest techniques. It was a mix of academic work and special-effects clips from unreleased Hollywood movies.
Every year, the videos would include some important component that had been missing the year before. Shadows! Diffuse lighting! Interaction of light with texture! I’d gaze upon the adventurer bathed in flickering torchlight, and marvel at how real it looked. Then the next year I’d laugh at how cartoonish that adventurer’s hair had been, after watching a new algorithm that simulated the way hair flows when people move.
In the late 80’s I would have thought this looked sooooo real I think AI is a little like that: we’re so (legitimately!) impressed by each new model that we can’t see what it lacks… until an even-better model comes along. As I said when I first started blogging about AI: as we progress toward an answer to the question “can a machine be intelligent?”, we are learning as much about the question as we are about the answer.
(Case in point: in the press briefing for the GPT-5 launch, Sam Altman said that we’ll have AGI when AIs get continuous learning. I’ve never heard him point to that particular gap before.)Moravec's paradox states that, in AI, “the hard problems are easy and the easy problems are hard”1 – meaning that the most difficult things to teach an AI are the things that come most naturally to people. However, we are often surprised by which things turn out to be easy or hard. You might think running is easy, until you see a cheetah do real running.
The accepted explanation for Moravec’s paradox is that some things seem easy to us, because evolution has optimized us to be good at those things, and it’s hard for clumsy human designs to outdo evolution. Evolution didn’t optimize us for multiplying large numbers or shifting gigantic piles of dirt, and so crude constructions such as calculators and bulldozers easily outperform us.
With that in mind: evolution would laugh if it saw how crude our algorithms are for training neural networks.Evolution’s grin might fade a bit when it sees how much sheer scale (of computing capacity and data) we can devote to training a single model2. A child’s intellectual development is driven by processes far more sophisticated than our procedures for training AIs, but that child has access to only a tiny fraction as much data.
The human genome (DNA) contains a few billion bits of information. Loosely speaking, this means that you are the product of a design that reflects billions of decisions, most of which have been ruthlessly optimized by evolution. Not all of those decisions will be relevant to how the brain works: your DNA also includes instructions for the rest of your body, there’s a certain amount of junk that hasn’t been optimized away yet, etc. But still, the design of our brains probably reflects hundreds of millions of optimization decisions.
I don’t know how many carefully optimized decisions are incorporated into the design of current LLMs3, but I doubt it comes to hundreds of millions. This is why I believe current AI designs are very crude.

Sample-Efficient Learning
When comparing human and AI capabilities, one important concept is “sample-efficient learning”. This refers to the ability to learn a new idea or skill from a small number of examples or practice sessions. In general, current AI models are much less sample-efficient than we are: a teenager learns to drive in less than 100 hours; Waymo vehicles have logged millions of hours and are still working their way up to driving on the highway, in snow, etc.
(This suggests that sample-efficient learning is one of the things evolution optimized us for.)“Sample efficiency” is probably a crude label for a complex tangle of capabilities. Just as there are many flavors of intelligence, there must be many flavors of sample efficiency. Some people argue that true intelligence is in fact more or less the same thing as sample efficiency.
Here are some examples of sample efficiency in humans: learning to drive a car in a few dozen hours. Figuring out the rule in an ARC-AGI task from just a couple of examples. Learning the ropes at a new job. Sussing out the key trick to solve a difficult mathematical problem. Are these all basically the same skill?
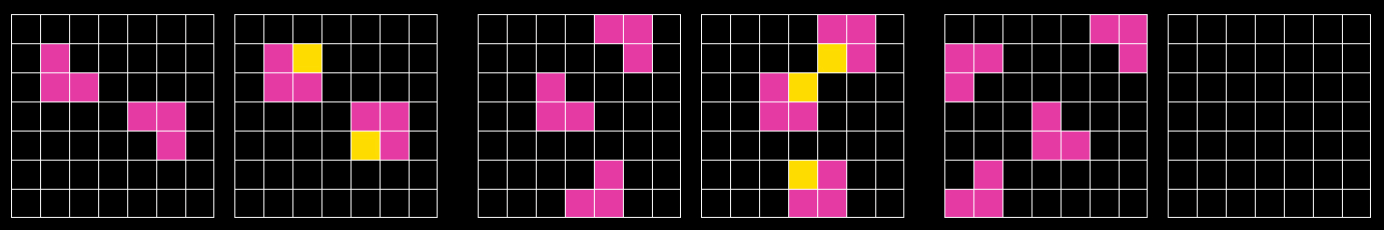
In this ARC-AGI puzzle, the goal is to look at the first two pairs of images, identify the rule, and apply it to the last image. It’s quite doable for people, and quite challenging for AIs. I often encounter the assertion that LLMs are sample-efficient learners within their context window. That is, while they need many examples of a concept to learn that concept during the training process, they can (it is said) quickly pick up a new idea if you supply a few targeted examples while asking them a question.
But if this were true, you’d think they’d be able to handle ARC-AGI puzzles (see the example image just above)4. Maybe they’re only good at picking up ideas from an example, if they’d already learned that idea during their original training? In other words, maybe in-context learning is helpful at jogging their memory, but not for teaching new concepts.Is sample-efficient learning a singularly important step on the path to AGI? If so, could other strengths of large language models (e.g. their superhuman breadth of knowledge) compensate for the lack of sample efficiency?
“Judgement” and “insight” also seem like crude labels that will turn out to encompass many different things. Will these things transfer across domains? If we develop a model that has judgement and insight in mathematics or coding, will it have a big head start on developing those same capabilities in other, messier domains? Or will current AI architectures struggle to generalize in this way? For that matter, are people able to transfer judgement, insight, and taste from one domain to another?
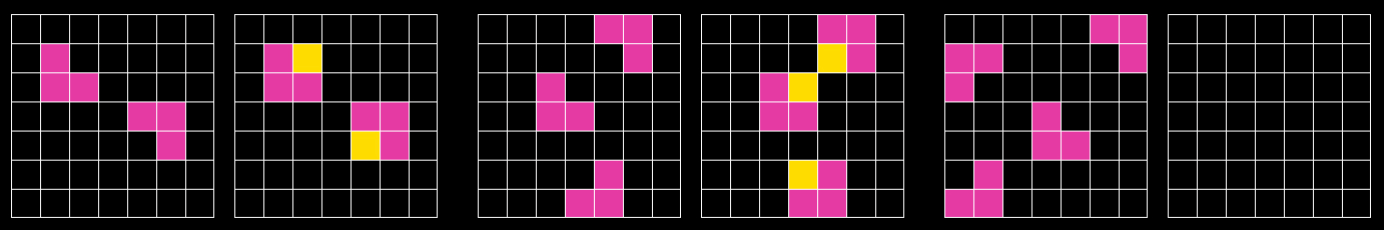
Crystallized and Fluid Intelligence
AIs have been demonstrating what arguably constitutes superhuman performance on FrontierMath, a set of extremely difficult mathematical problems. But they mostly seem to do it “the wrong way”: instead of finding elegant solutions, they either rely on knowledge of some obscure theorem that happens to make the problem much easier, or grind out a lengthy brute-force answer.
Does this matter? I mean, if you get the answer, then you get the answer. But in mathematics, much of the value in finding a proof is the insights you acquired along the way. If AIs begin knocking off unsolved problems in mathematics, but in ways that don’t provide insight, perhaps we’ll still need mathematicians to do the real work of advancing the overall field. Or maybe, once AIs can solve these problems at all, it’ll be a short step to solving them with insight? My instinct is that it’s not a short step, but that could be cope. In any case, the big question is what this tells us about AI’s potential in applications other than mathematics. What portion of human activity requires real insight?
Source: https://x.com/dmimno/status/949302857651671040 To put it another way: compared to people, large language models seem to be superhuman in crystallized knowledge, which seems to be masking shortcomings in fluid intelligence. Is that a dead end, great for benchmarks but bad for a lot of work in the real world? Or is it a feasible path to human-level performance?
(Taren points out the irony that while LLMs know far more facts than people, they also routinely get facts wrong – “hallucinations”.)The best public estimate is that GPT-4 has 1.8 trillion “parameters”, meaning that its neural network has that many connections. In the two and a half years since it was released, it’s not clear that any larger models have been deployed (GPT-4.5 and Grok 3 might be somewhat larger).
The human brain is far more complex than this; the most common estimate is 100 trillion connections, and each connection is probably considerably more complex than the connections in current neural networks. In other words, the brain has far more information storage capacity than any current artificial neural network.
Which leads to the question: how the hell do LLMs manage to learn and remember so many more raw facts than a person5?
One possible answer: perhaps models learn things in a shallower way, that allows for more compact representations but limits their ability to apply things they’ve learned in creative, insightful, novel ways. Perhaps this also has something to do with their poor sample efficiency.
Solving Large Problems
When projecting the future of AI, many people look at this graph:
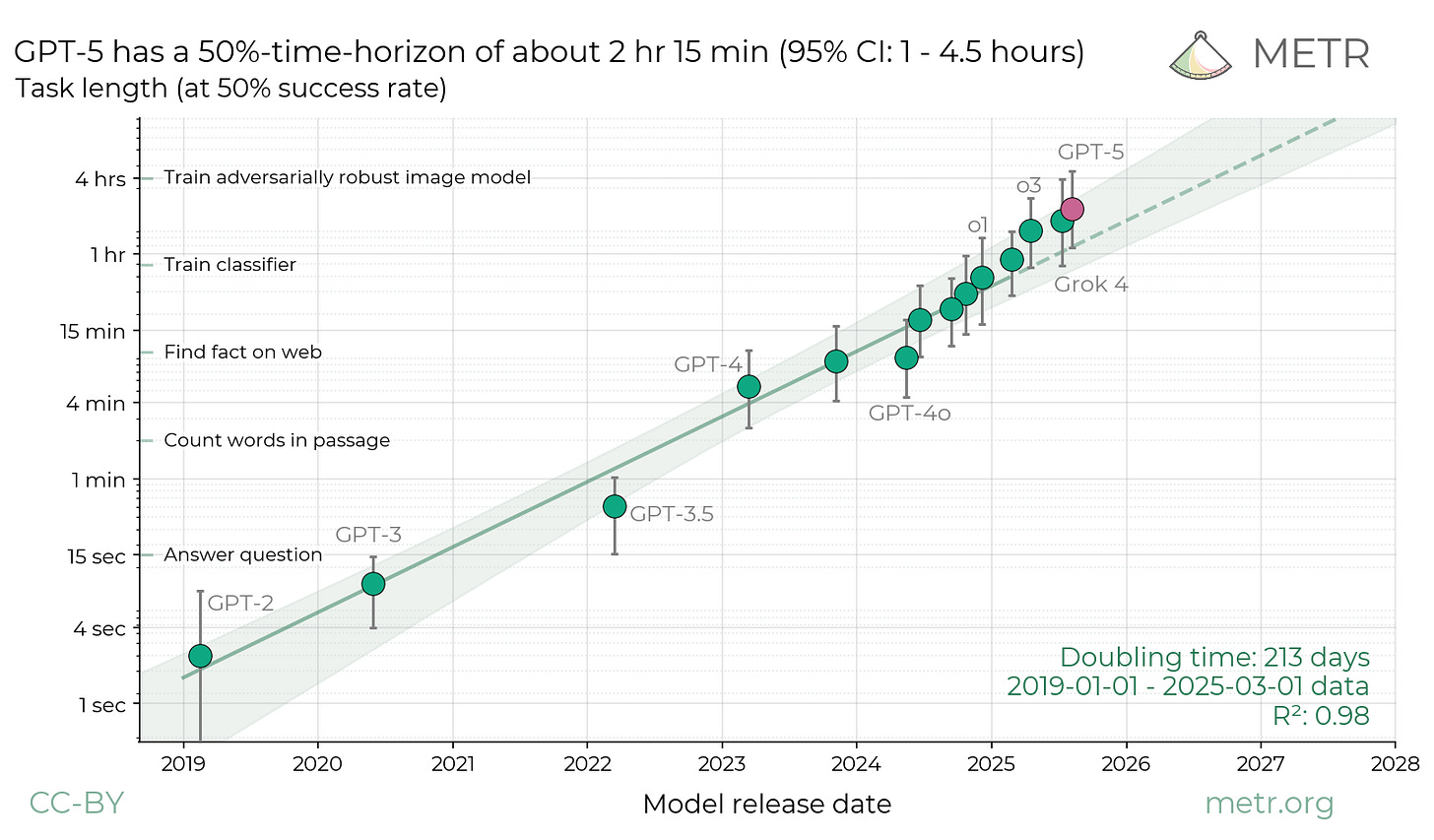
This is the latest version, updated to include GPT-5 (source) It shows that the size of software engineering tasks an AI can complete has been roughly doubling every 7 months. This trend has held for over 5 years (arguably6), during which the achievable task size increased from around 3 seconds to around 2 hours. Why should the trend be so steady?
It’s not obvious that the difficulty that AI will have in completing a task should increase steadily with the size of the task. If a robot could assemble 10 Ikea bookshelves, it could assemble 20 bookshelves. If a coding agent can create a form with 10 fields, it can probably create a form with 20 fields. Why is it that if an AI can complete a 10-minute project, it still may not be able to complete a 20-minute project? And why does the relationship between time and difficulty hold steady across such a wide range of times?
I think the predictable(-ish) trend of AIs tackling larger and larger software engineering tasks has something to do with large tasks containing a fractal distribution of subtasks. There is a fuzzy collection of tactical and strategic skills involved, ranging from “write a single line of code” to “design a high-level architecture that breaks up a one-month project into smaller components that will work well together”. Larger tasks require high-level skills that are more difficult for AIs (and people) to master, but every task requires a mix of skills, tasks of the same size can involve different mixes (building one fancy model airplane vs. 20 bookshelves), and the fuzzy overlaps smooth out the graph.Even so, if the doubling time for task sizes holds steady at 7 months, the consistency of that trend will point to something deep about the nature of large tasks vs. small tasks, and the cognitive skills that people and LLMs bring to each.
It's been argued that the skills needed to solve tasks of a given size flatten out as you progress toward larger tasks. That is, there’s a big difference between solving 1-minute vs. 2-minute tasks, but (the argument goes) once you can carry out a project that requires a full month, you’re pretty much ready to tackle two-month projects. And so we should expect to see an acceleration in the size of tasks which AIs can handle – it should start doubling more frequently than every 7 months.
I don’t share this intuition. I’d expect increases in task length to keep upping the difficulty, even when the base line task length is already large. For instance, if I’m approaching a 2-month project, perhaps I should start out by spending a couple of weeks prototyping several different approaches, or taking an online course to learn a new programming technique. Those are high-level ideas that might not make sense if I only have one month.
Heck, maybe we should expect 1 month → 2 months to be a bigger leap than 1 minute → 2 minutes: the former is an increase of one month, the latter is an increase of only one minute! I wouldn’t actually expect successive doublings to get more difficult, but it’s not obvious to me why we should expect them to get easier, either.If you’ve mastered tasks that take a single day, what additional skills do you need to handle week-long, month-long, or year-long projects? Do we have any clear idea of what those skills are? I suspect that we don’t understand them very well, that we tend to discount the skills involved, and that this contributes to some people having (what I believe are) unrealistically short estimates of the time it will take to develop AGI.
Model developers are working hard to train their models to carry out complex tasks. The current approach involves letting the model attempt practice tasks, and tweaking the model after each success or failure. Roughly speaking, this approach generates one bit of learning for each attempted task.
This is feasible under current conditions, when models are mostly handling tasks that take a few seconds to a few minutes to carry out. What happens when we’re trying to train models to independently manage month-long projects? One bit of learning per month is a slow way to make progress. Perhaps sample-efficient learning becomes more important as you attempt longer tasks.One workaround to the difficulty of learning how to carry out long tasks is to break them into subtasks, and handle each subtask as a separate project. But this simplifies away many important aspects of problem solving. A large project does not neatly decompose into tidy subprojects.
For instance, when I tackle a subtask during a large software project, the result is not just that a certain chunk of the code gets written. I come out with a slightly deeper understanding of the problem. I may have learned new things about the existing codebase. I may have hit upon a handy trick for testing the kinds of operations that this code performs, or had an insight about the data being processed. I may have gotten some little nudge that will eventually accumulate with 20 other nudges across other portions of the project, eventually leading me to rethink my entire approach. If the subtask is assigned to a separate agent, whose memories are discarded as soon as the subtask is complete, none of that learning can take place.At the same time, perhaps efficiently managing a complex month-long project is not something that evolution optimized us for? In which case AIs might eventually blow past us the way they did with chess.
Continuous Learning
“Continuous learning” refers to the ability to assimilate new skills and knowledge while carrying out a task. People are of course continuous learners. Current LLMs are not: a model like GPT-5 first undergoes “training”, and then is released for use, at which point the model is frozen and can never learn anything new.
Continuous learning seems related to sample-efficient learning. Cutting-edge models today are trained on tens of trillions of “tokens” (roughly meaning, words). This is astronomically more data than a person might encounter over the course of a project. So to learn new things on the fly, you need to be sample-efficient.Continuous learning seems related to the way models often struggle when we try to integrate them deeply into our work. Think about your experience on the first day of a new job: you struggle, too. You don’t know how to do anything, you don’t know where to find anything. Every little task requires conscious deliberation and extensive research. Roaming around the internal website, not to find the information you need, but just to get a sense of where to look; asking someone for help in figuring out who to ask for help.
Everything that current models do, they do in their first hour on the job.There’s an argument that once AIs have mastered continuous learning, we’ll apprentice them to do every possible job, and amalgamate the resulting learnings into a single model that’s pre-trained to be good at everything. It’s not obvious to me that this will work. The accountant-bot will have taken its neural network in a different direction than the therapy-bot, and jamming two different things together may not work out any better than it did for Jeff Goldblum in The Fly. This is like an extreme version of “distributed training” (using multiple data centers to train a single model), which is something that has only been demonstrated in limited ways, requiring close coordination between the different learning centers.
A model that has been working as an apprentice accountant will have learned a lot of things about accounting, but also a lot of sensitive details regarding specific clients. Those details would have to somehow be excluded from the knowledge aggregation process, both for privacy reasons, and to avoid overwhelming the unified model with unimportant detail.
Arguably, “continuous, sample-efficient learning” is a good description of the way you keep track of what you’re doing over the course of a project. You accumulate knowledge of the project’s context – for instance, if the assignment is to add some new functionality to a piece of software, you’ll need to learn how the existing code works. As you work, you also remember what you’ve already done and what blind alleys you’ve explored.
It’s been proposed that LLMs can rely on their “context window” – the transcript of everything you’ve said to them, everything they’ve said to you, and their own internal monologue as they work through the task – as a substitute for continuous learning. I have trouble accepting that this will scale up to large projects. Current LLM architectures make it very expensive to keep increasing the context window, and this seems like a fundamental barrier. People are able to fluidly “wake up”, “put to sleep”, consolidate, and otherwise manage sections of our memory according to need, and today’s LLMs cannot.
Phase Changes as We Get Closer to AGI
Currently, when AIs are used in the workplace, they are a tool, an extra ingredient that is sprinkled into processes that remain fundamentally human-centered. A human manager assigns tasks to a human worker, who might rely on an AI to handle some isolated subtasks. Even in the infrequent examples where AI is reported to have written most of the code for some software project, that’s still happening in small to medium-sized chunks, organized and supervised by people.
When AIs start to do most of the higher-level work, workplace dynamics will change in hard-to-anticipate ways. Futurists like to point out that AIs can run 24 hours a day, never get bored, can be cloned or discarded, and do many things much faster than people. So long as people are the glue that holds the AI workers together, all this is of limited consequence. When the AIs take center stage, all of those AI advantages will come into play, and the result will be something strange.
Think about a long vacation when you really unplugged – not in December when nothing was happening, but during a busy period. Think about how much catching up you had to do afterwards. Now imagine if every single morning, you discover that you have that much catching up to do, because the AI team you’re attempting to supervise has done the equivalent of two weeks of work while you slept. You’ll no longer be a central participant in your own job; it’ll be all you can do to follow the action and provide occasional nudges.
The transition from AI-as-a-tool to people-are-mostly-spectators could happen fairly quickly, like a phase change in physics.An important moment in the history of AI was the conversation in which Bing Chat, built around an early version of GPT-4, tried to break up a New York Times reporter’s marriage. This was far outside the behavior that Microsoft or OpenAI had observed (or desired!) in internal tests. My understanding is that they had only tried short, functional interactions with the chatbot, whereas reporter Kevin Roose carried out an extended conversation that took the bot into uncharted territory.
This may be related to the recent phenomenon where for some people, extended interactions with a chatbot, over the course of weeks or months, appear to be exacerbating mental health issues. The common theme is that when machines transition from bit parts to leading roles, unexpected things happen.
(Those unexpected things don’t have to be bad! But until AIs get better at managing the big picture, and/or people learn a lot more about the dynamics of AI-powered processes, the surprises will probably be bad more often than not.)It’s widely recognized that AIs tend to perform better on benchmark tests than in real-world situations. I and others have pointed out that one reason for this is that the inputs to benchmark tasks are usually much simpler and more neatly packaged than in real life. It is less widely recognized that benchmark tasks also have overly simplified outputs.
We score an AI’s output on a benchmark problem as “correct” or “incorrect”. In real life, each task is part of a complex web of ongoing processes. Subtle details of how the task is performed can affect how those processes play out over time. Consider software development, and imagine that an AI writes a piece of code that produces the desired outputs. This code might be “correct”, but is it needlessly verbose? Does it replicate functionality that exists elsewhere in the codebase? Does it introduce unnecessary complications?
Over time, a codebase maintained mostly by AI might become a bloated mess of conflicting styles, redundant code, poor design decisions, and subtle bugs. Conversely, the untiring nature of AI may lead to codebases that are inhumanly well-maintained, every piece of code thoroughly tested, every piece of documentation up to date. Just as it was hard to guess that extended conversations could lead early chatbots into deranged behavior, it is hard to guess what will result from giving a coding agent extended responsibility for a codebase. Similarly, it is hard to guess what will result from putting an AI in charge of the long-term course of a scientific research project, or a child’s education.
Other Thoughts
In every field, some people accomplish much more than others. Nobel-winning scientists, gifted teachers, and inspiring leaders are held up as an argument for the potential of “superintelligence”. Certainly, the argument goes, it should be possible to create AIs that are as capable as the most capable people. An Einstein in every research department, a Socrates in every classroom. And if it’s possible for an Einstein to exist, why not an (artificial) super-Einstein?
I find this argument compelling up to a point, but I suspect we may incorrectly attribute the impact of great scientists to brilliance alone. Einstein contributed multiple profound insights to physics, but he did that at a time of opportunity – there was enough experimental data to motivate and test those insights, but that data was new enough that no one else had found them yet7. Edison’s labs originated or commercialized numerous inventions, but his earlier successes provided him with the resources to vigorously pursue further lines of research, and the opportunity to bring his further inventions to market.
Steve Jobs’ accomplishments owed much to his ability to attract talented employees. Great leaders achieve success in part by edging out other leaders to rise to the top of an organization. If AI allows us to create a million geniuses, we won’t be able to give them all the same opportunities that (some of) today’s geniuses are afforded.As OpenAI progressed from GPT-1 to GPT-2 to GPT-3 to GPT-4, the theme was always scale: each model was at least 10x larger than its predecessor, and trained on roughly 10x as much data.
In the two and a half years since GPT-4 launched, frontier developers have continued to increase the amount of data used to train their models, but model sizes are no longer increasing; many subsequent cutting-edge models seem to be smaller than GPT-4. This has been interpreted as a sign that the benefits to scaling may have stalled out. However, it might simply be that no one would have much use for a larger model right now, even if it was more intelligent. All of the leading edge AI providers (with the possible exception of Google?) are clearly capacity constrained – they already can’t offer all of their goodies to everyone who would like to use them. Larger models would make this much worse, both increasing demand (presumably, if models were smarter, people would use them more) and reducing supply.
We might not see much progress toward larger models until we’ve built enough data centers to saturate demand. Given how much room there is for AI to diffuse into further corners of our personal and work lives, that could be quite a while.Everyone is sharing this graph, which compares the level of investment in railroads in the 1880s, peak telecommunications infrastructure spending around the 5G rollout [EDITED to fix my confusion between the dot com and 5G telecom investment waves], and AI data centers today:
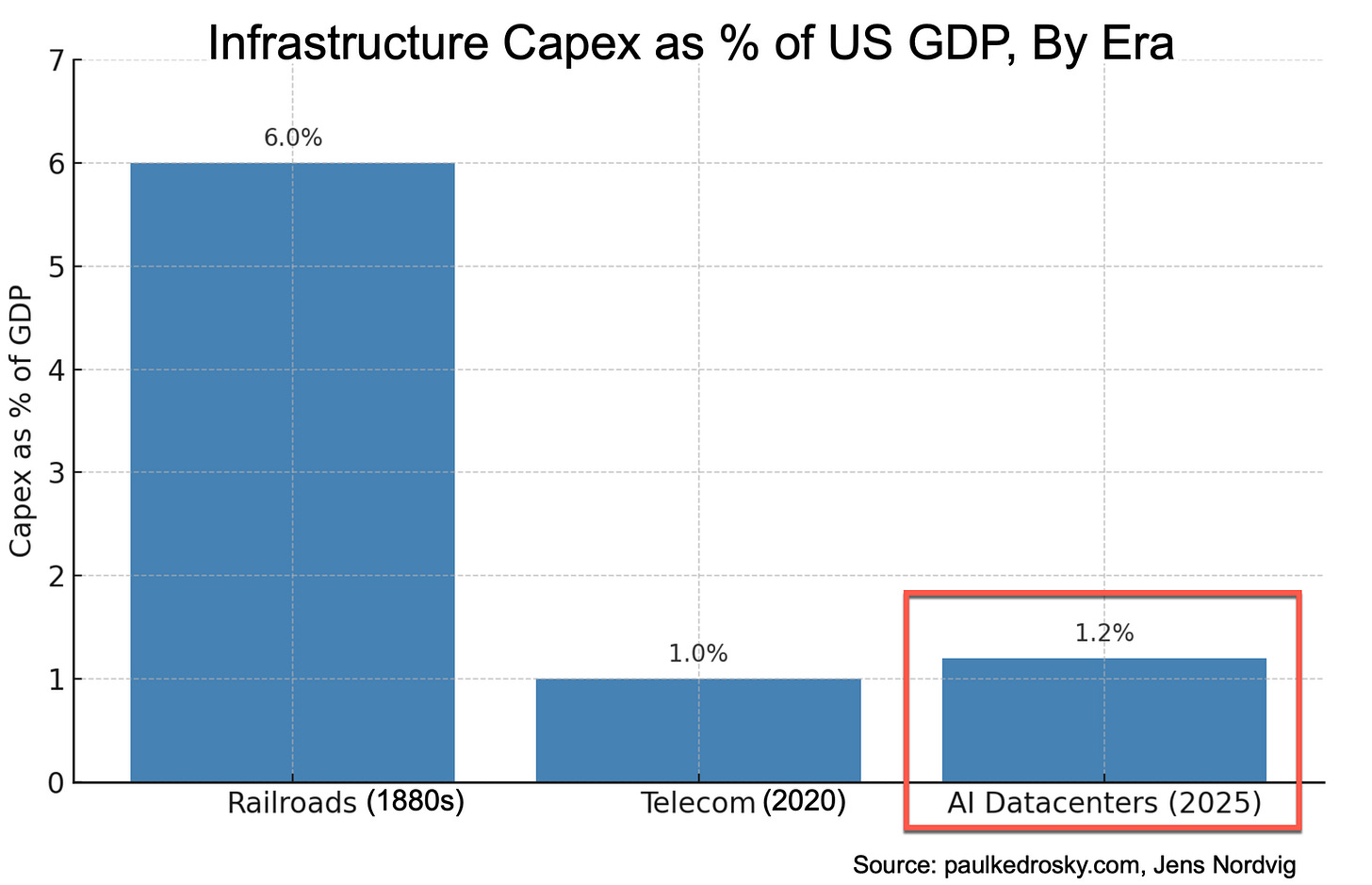
source: https://paulkedrosky.com/honey-ai-capex-ate-the-economy/ The usual takeaway is: wow, the AI boom (or bubble) is bigger than the dot-com bubble. I don’t understand why people aren’t focusing more on the fact that railroad investments peaked at three times the dot-com boom and AI datacenter rollout put together. Holy shit, the 1880s must have been absolutely insane. The people of that time must have really believed the world was changing, to be willing to sustain that level of investment. (I’ve seen arguments that the pace of change in the late 1800s and early 1900s made our current era seem positively static. Steam power, electricity, railroads, the telegraph, telephones, radio, etc. This graph makes that a bit more visceral.)
(I also wonder whether these numbers may turn out to be wrong. Some commentator noted that older GDP figures may be misleading because the informal economy used to play a much larger role. When a startling statistic spreads like wildfire across the Internet, it often turns out to be incorrect.)
Thanks to Taren for feedback and images.
This quote is from a restatement of the paradox by Steven Pinker. Moravec’s original statement, in 1988:
It is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility.
Evolution completely outclasses us at nuanced optimization of complex systems. Conversely, our great advantage is the ability to precisely coordinate efforts and resources on a grand scale.
Thus, evolution wins at: low-temperature chemical processing; mechanical dexterity; sample efficient, adversarially robust learning. But we can create: steel mills, moon rockets, skyscrapers, yottaflop training runs.
If and when AIs are able to match evolution at subtle design, while retaining (or, inevitably, exceeding) humanity's existing capability for marshaling vast resources... things are gonna get interesting.
Large Language Models, such as GPT.
Yes, the some models can now post high scores on the original ARC-AGI-1 test, but they still struggle with ARC-AGI-2 and ARC-AGI-3. Also, yes, it seems likely that one reason models struggle on ARC-AGI problems is that they don’t have much experience looking at pixelated images. But I still stand by the observation that models seem to only be selectively skilled at in-context learning.
I asked ChatGPT, Claude, and Gemini to compare the number of “facts” known by a typical adult to a frontier LLM. They all estimated a few million for people, and a few billion for LLMs. To arrive at those estimates, they engaged in handwaving so vigorous as to affect the local weather, so take with a grain of salt. (ChatGPT transcript, Claude transcript, Gemini transcript)
The data does suggest that the rate of progress has accelerated recently, perhaps to a 4 month doubling time, but this is debated and there isn’t enough data to be confident in either direction.
Though some of the relevant data had been available for several decades.
It takes about fifteen years for a human to learn to drive a car. We do not let week-old infants get behind the wheel, as we would if a few hundred hours was accurate.
Great list of questions. I agree that the distance to AGI is large. But a major point of people who believe in short timelines is that they expect (or take into account the possibility) of recursive self-improvement. That would be a good topic for additional questions :)