
45 Thoughts About Agents
The layer of the AI stack that evolves fastest – and may have the most impact


One of my most popular posts ever was 35 Thoughts About AGI and 1 About GPT-5, a grab bag of musings about the path to AGI (plus a snarky aside about GPT-5).
Here is a fresh collection of musings, this time about AI agents.
I had trouble making time to write this: I’m so drawn into using agents that it’s hard to make time to write about agents. This isn’t an isolated phenomenon; many people are tweeting about getting sucked into vibe coding at every available minute.
This is driven by the astonishing productivity of current AI coding agents in particular, especially when used in ways that play to their strengths. I’m using Claude Code to build a ridiculously ambitious set of productivity tools for my own personal use. A single sub-project involves deep integrations with Gmail, Slack, WhatsApp, Twitter, Signal, SMS, Substack, Pocket Casts, Notion, Google Drive, Google Contacts, Google Calendar, and more. As recently as last year, it would have been insane for me to even contemplate such an undertaking, let alone as a side project. With today’s tools, I knocked off most of the integration work over the course of a weekend. AI models are providing the intelligence the app will need to make use of all this data, and coding agents are handling the tedious integration chores.
After decades as a prolific coder, I stopped cold in early 2023, leaving me quite rusty. That rust hasn’t been the slightest impediment. In fact, I suspect it might be helpful – the habits I would have had to unlearn have already faded, and it’s been easy for me to slip into the habit of letting the AI write all the code. I am still using my high-level design experience to guide the agents; interestingly, those skills don’t feel rusty at all. I wonder what it is about low-level coding technique vs. high-level design skills that makes the latter easier to retain, and what this might say about which human skills will remain relevant.
My experience doesn’t seem to be in any way unique – apparently a lot of engineers who had gotten out of the business of producing code themselves are getting back in:
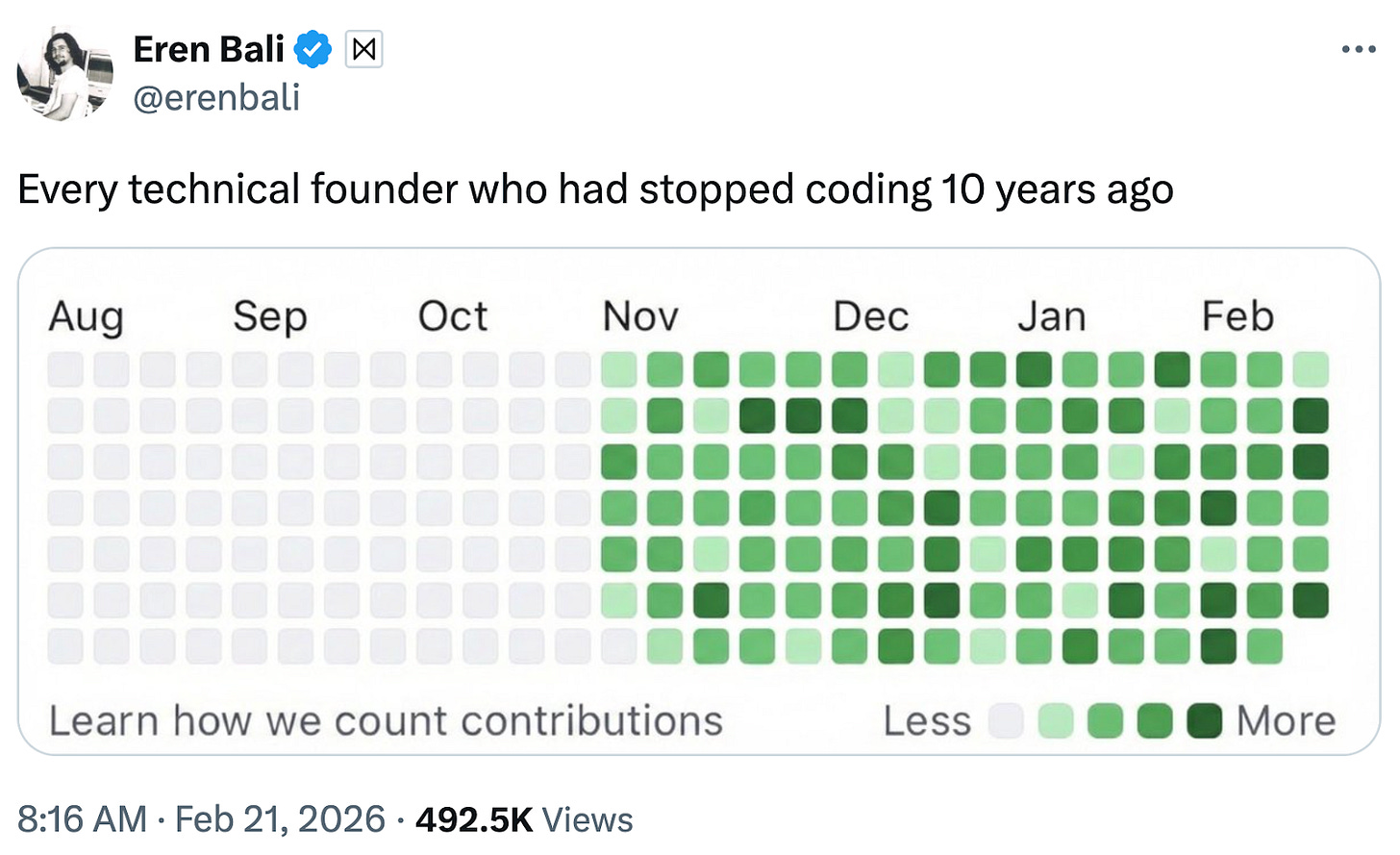
This is an example of a broader phenomenon: AI agents are going to change the nature of work. Some jobs will get more efficient, some will go away, some new jobs will arise. Some will become more fun, as AI automates the annoying part; some will become more stressful, as AI automates the easy or rewarding part. In this post, I’m not going to explore the question of how jobs and workers will be impacted overall. But I do want to highlight that things will change in many ways, often unpredictable.
I’m able to dive back into coding because Claude Code has gotten capable enough that I can be productive without editing, or even looking at, the actual code. My impression is that this was not the case prior to the November release of Opus 4.5. This is a reminder that threshold effects are a huge source of unpredictability for AI’s impact.

Why Agents Are Such a Big Deal
Suddenly, all of the AI news seems to be about agents. OpenClaw made waves because it’s an AI agent that can act autonomously. In the recent “SaaSpocalypse”, the market cap of Software-as-a-Service (SaaS) companies fell by over one trillion dollars, driven by fears that coding agents will make mass-market software obsolete. When people talk about the results they’re getting from the latest models, like Opus 4.6 and GPT-5.3-Codex, they’re talking about using them to power an agent like Claude Code.
One reason agents are having such an impact is that they are the layer of the AI stack that evolves most rapidly. A foundation model is a gigantic monolith – a single data file containing trillions of mysterious numeric weights. Updating it, even for an incremental release like Opus 4.5 → 4.6, is a big project. Agents, by contrast, are traditional software, and can be updated incrementally – tweak a prompt here, add a new integration there. Model releases come months apart; Claude Code sometimes has multiple releases in one day. The ship → get feedback → improve → ship cycle for an agent can be very fast.
Actually I lied about where change comes fastest: some users are evolving their behavior even faster than the agents. My Twitter timeline is full of crazy but productive new ways that people are finding to use these tools. For example, here’s one epiphany (among many!) that I was late to the game on: agents are comparatively weak at high-level decision making, but they make execution cheap. So sometimes, instead of trying to choose the right path, you can just tell the agent to explore every path.

Another adage that agents shoot to hell: “if you don’t have time to do it right, when will you have time to do it over?”
It was always obvious that serious AI capabilities would require agents of some sort. Any intelligence, whether silicon or carbon based, can do more by feeling its way through a problem than it can do in a direct leap to a finished result1. The famous METR “time horizon” graph, showing the time scale of coding tasks that an AI can attempt with some hope of success, seems to have accelerated sharply when the first “reasoning model” – roughly, the first model trained as an agent – was released.

What Exactly Is an Agent?
People use the term “agent” pretty loosely. The core idea for me is a system that pursues a goal rather than following a script.
You can achieve a goal by following a script, but it doesn’t work very well. Scripts are brittle. Suppose I want an AI system to book a flight to New York. I could give it a step-by-step script, and it might even work, on a good day. But if the airline booking procedure has changed, or an unexpected circumstance arises, a script-following bot will get stuck, or forget to enter my frequent flyer number, or book the wrong kind of ticket, or worse. People often use the word “agent” to describe systems that are just following scripts. But I’m going to stick to the idea that a system is only an agent to the extent that it can robustly pursue a goal, even in the face of unanticipated circumstances.

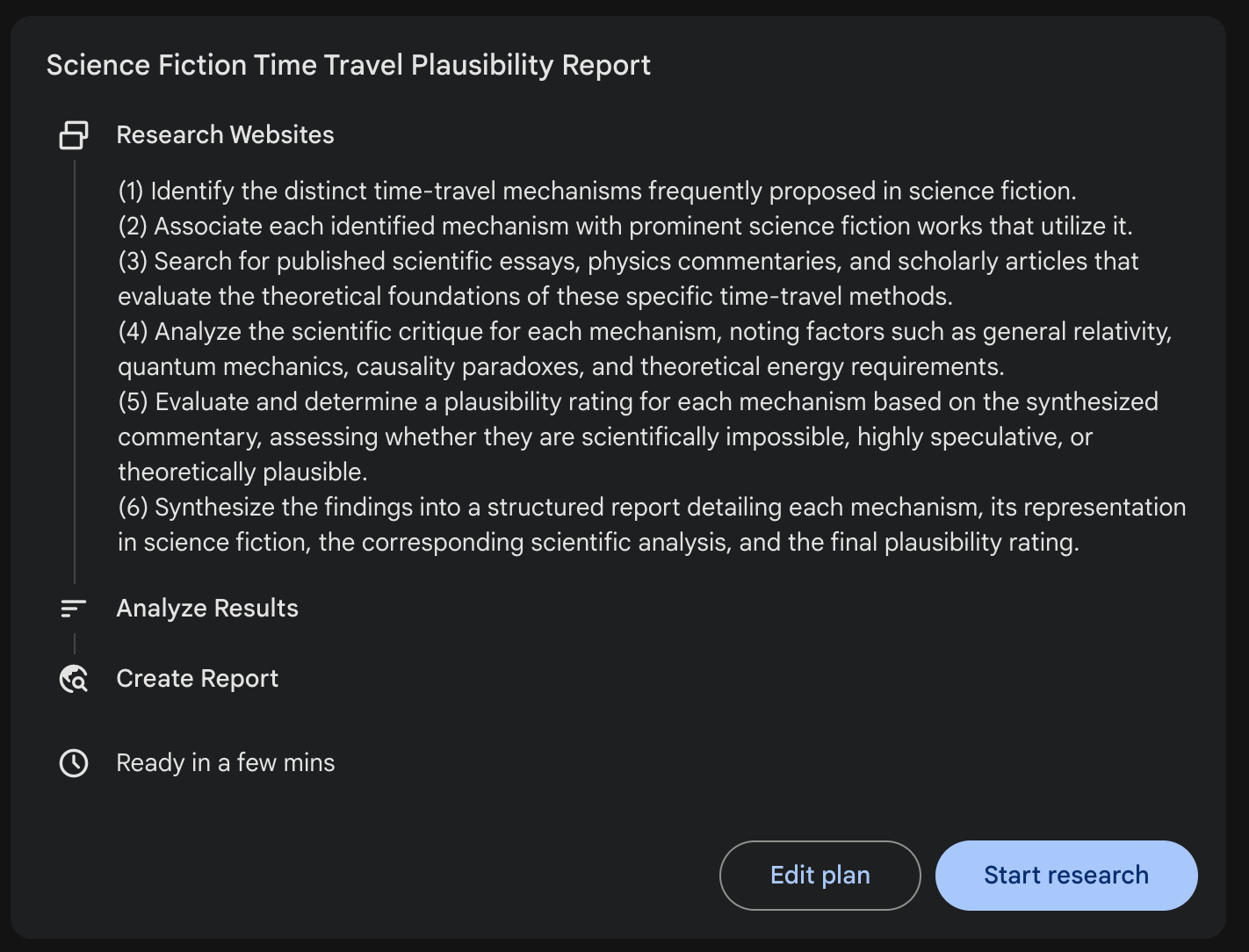
The Gemini Deep Research tool is an example of a scripted system. You give it a question, it generates a plan and carries it out. Sometimes this goes well, sometimes not. In step 5 of the plan below, it might become clear that some additional research on a particular aspect of theoretical physics is called for. A rigid plan doesn’t allow for that. By contrast, if you select “thinking” mode in any of the leading chatbots and ask a question requiring research, they will take a flexible approach, adjusting course based on questions that arise over the course of the investigation.
Current agents can work toward a goal, but the way they go about it is sometimes alarming. They’ll make strange decisions or veer off in odd directions. Yes, people do that too, but current agents are worse, and weirder. For instance, I pointed out that one element of a website it had built for me didn’t look right when my phone was in dark mode, and instead of fixing that element, it tried to prevent any part of the page from entering dark mode, resulting in the following bit of lovely web design.

Despite this, they get to the right outcome for an increasing variety of tasks of increasingly large scope. That’s partly through sheer persistence. If at first they don’t succeed, they’ll try, try again, and again, and again. Yes, people do that as well, but agents can be inhumanly persistent and patient. (They can afford to be! Their time is much less valuable, especially if measured in actions rather than minutes.)
As always, AIs partially compensate for a lack of deep understanding with an incomprehensible breadth of training on zillions of specific tasks. They may struggle with novel situations, but they will surprise you with how many problems they already know how to solve. Using breadth to compensate for lack of depth has always been part of the LLM story. The first “L” in LLM stands for Large, which relates to a large volume of training data.

Using Agents Effectively
To get value from current agents, you need to find agent-shaped pieces in your current workflow. They’re not always obvious. And you can get more value if you’re willing to reshape your workflow so that it contains more agent-shaped tasks.



Many people have pointed out that if you just naively hand pieces of work to an agent, your productivity can actually go down. It’s easy to fall into a cycle where an agent produces something for you, you provide feedback, the agent makes revisions, you check it again, ad infinitum. This feels productive (the agent is doing so much work!), but before you know it, you’ve spent more time giving feedback to the agent than it would have taken you to do the work yourself.
Advanced users understand that the key is putting the agent in a position to check its own work. The agent’s strength isn’t flawless execution, it’s the speed and stamina to keep plugging away. But it doesn’t necessarily realize this – its instinct is to constantly ask for your approval. You have to be very explicit in instructing it what constitutes a successful outcome.
Current agents are notoriously focused on the main thrust of their assigned task, to the expense of all else. For instance, I will tell an agent to make a change to some code and then make sure all of the tests pass. It will beaver away for 10 minutes, generating a flood of output, and report success. And then I’ll read back through the output, notice a casual remark that “seven tests can’t be adapted to the new code, so I’ll just remove them”, and smack my forehead. (Unfortunately, smacking the agent’s forehead is not an option.)
The best practice is to have one agent do the work, and then a separate agent check the work. This isn’t because the first agent isn’t smart enough, it’s because these agents are trained to be so goal-oriented that they struggle to hold onto more than one goal at a time.One hallmark of a skilled user of agents is their resourcefulness in finding ways for the agent to check its own work. Here’s an example, taken from my post on Hyperproductivity:
…when Jesse [Vincent] uses his “Superpowers” tool to codify a skill, the tool uses its test-driven development module to verify that the new skill has been implemented correctly. It generates an example of a task that the new skill is meant to help with, verifies that it is unable to complete that task without the new skill, and then checks to see whether it can complete the task once the new skill has been installed.
The need for clear success criteria applies to people as well as AI agents. But we’re more proactive than AIs at finding ways to check our work, and at sussing out unstated requirements. I wonder whether this “eh, that’s probably good enough” attitude is a fundamental weakness of current agent architectures, or just a flaw in the feedback they’re given during training.
People often argue that AI tools can be useful even if they’re unreliable, because it’s easier to check the AI’s output than to do the work yourself. I think this is overstated. Sometimes it’s much easier to make a thing than to verify the thing. For instance, you can sometimes build a large spreadsheet in just a few minutes, using repeating formulas and smart autofill features. For someone else to poke through all 1000 cells in that spreadsheet and make sure you did it correctly might take a lot longer. Some kinds of work are hard to hand to an agent, for the same reason.
Because I don’t want to have to check an agent’s work, I find that it’s often worthwhile for me to spell out in great detail how I’d like it to go about a task – minimizing its opportunities to screw up. One of my few viral tweets showed a detailed prompt I wrote for Claude Code (click the link above to see the full prompt).
It took me half an hour to write the prompt. But it would have taken me an entire day or more to write the code myself. And this prompt was enough for Claude to get absolutely everything right on the first try – and to give me the confidence to not spend time reviewing the work. This is an extreme example, but the principle often applies: 5 minutes of extra detail in the prompt can save an hour of reviewing flawed outputs.

People are building elaborate prompt systems, with names like Amplifier and Superpowers, to elicit more sophisticated work from agents. There is an enormous amount of work taking place here, mostly homegrown. Why aren’t companies like Anthropic and OpenAI incorporating these ideas into their agents (and the models themselves)? I think that all of this is so new that a thousand early adopters can explore new ideas faster than even nimble companies can absorb. End-user innovation is the fast-moving layer right now; successful ideas are incorporated first into the agents, and then the models.
It’s also the case that many of these prompt systems are designed to trade off thinking time for quality. They ask the agent to do the work four times and compare results, do endless critiques of its own work, and so forth. Anthropic and OpenAI may be holding off on incorporating extreme agent orchestration techniques into their baseline agents because they don’t have the computing capacity to support widespread use of those techniques.There’s a limit to how quickly you can climb the ladder of sophistication in use of agents. Before you can have an agent effectively checking its own work, you need a taste for checking the work yourself. Before you can manage a swarm of agents, you need to manage one agent. It’s helpful to read about what the experts do, but you can’t emulate them on day one.
Impact
People in my circles make fun of analyst Ed Zitron for his skepticism of AI. Below is a recent where’s-the-beef rant (click the image to view the complete thread). He’s arguing that even to the extent that AI is generating a lot of activity, that activity isn’t having much impact. And… I’m not sure he’s wrong? I’m still very confused as to how long it will take for AI capabilities, which are undeniably astonishing, to cash all the way out into large scale real world impacts – GDP growth, labor market disruption, improvements in health care outcomes, and so forth. When will all of this actually matter? How will we know? How should we even define “mattering”?

In particular, a lot of the energy people put into vibe coding seems to be devoted to making them more efficient at vibe coding. I can absolutely relate to this; I’ve been at it for about two months, and much of it has been spent this way. But of course if all we’re getting from vibe coding is better vibe coding, that supports Zitron’s point.

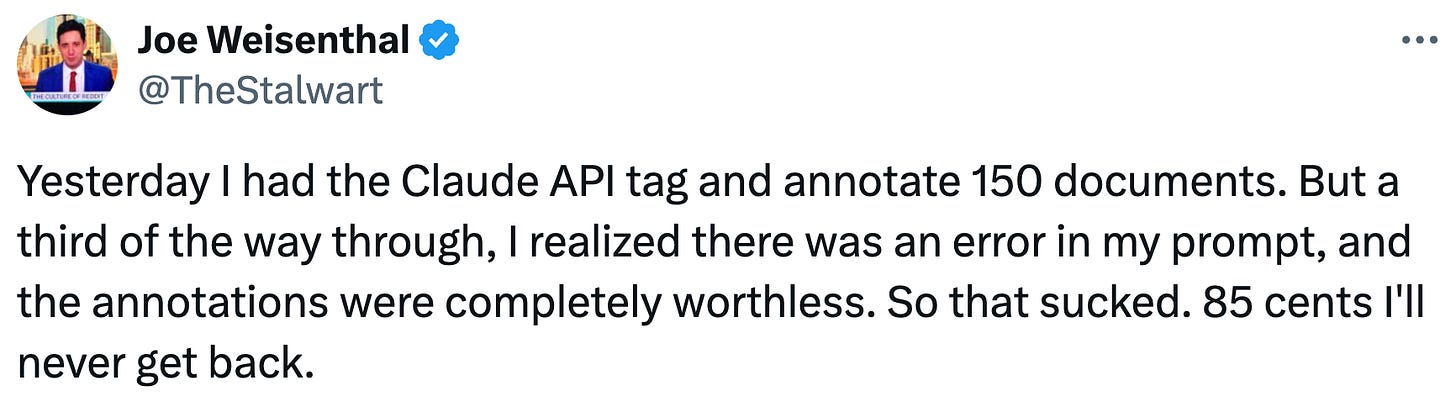
AI is extremely good at cranking out work that looks good at first glance but isn’t really worth using. Reporter Jessica E. Lessin presents an example: she had Claude Code generate slides for a presentation on her recent trip to Davos. The result, like so much AI work, was competent, but too bland to be of any value:
Overall, Claude’s slides were better than I expected. The themes it identified were high level: Mostly accurate, they included slides on the size of the AI infrastructure build-out, tech companies’ big bet on agentic AI and the growing number of creators using AI.
Claude did a capable job of identifying interesting parts of individual interviews, like the comments Amazon CEO Andy Jassy made about OpenAI and jobs.
It also added a few nice touches, like this line on the final slide: “Full interview transcripts available to subscribers.” It was reading my subscriber-acquisition–focused brain!
Yet the slides overall were pretty boring and too high level: They’d be useless to anyone who followed tech closely. [emphasis added]
On a related note, Tom Cunningham observes that AI can pull you away from doing the most important things, and toward the things that AI can do:
I believe many estimates of LLM productivity boosts are over-estimates because people are using them for cadillac tasks: things that would take you a long time unaided, but have only marginal additional value.
Despite all of this, AI agents are absolutely creating real value. To share a personal example, I vibe-coded an app that generates summaries of all the (many!) newsletters and podcasts I follow. It saves me a solid hour per day by letting me be choosier about which episodes I read / listen to. For the first time in years, I’m consistently keeping up with my reading queue. There are many, many such examples – they’re just mixed in with a lot of slop and Cadillac tasks.
Where Things Go From Here
Agents are going to progress rapidly, by any metric: usage, capabilities, impact. AI’s impact is the product of eight separate factors; pre-training, post-training, inference compute scaling, agent scaffolding, app design, user aptitude, workflow refactoring, and adoption. All eight are advancing, some quite rapidly. That will multiply out to a blistering pace of change. As I write this, it has been less than three months since the release of Opus 4.5 (kicking off the current wave of interest in coding agents), and we’ve already experienced further acceleration from Opus 4.6, dozens of updates to Claude Code, and rapid cultural evolution in where and how to best use agents.
We experienced a phase change at some point in the second half of last year. Opus 4.5 was probably the trigger. Previously, coding agents were useful tools, but they made plenty of mistakes, and getting reliable value out of them required expertise and careful workflow design. They’re now considerably more robust, to the point where non-technical users can vibe-code serious applications. There’s been a tipping point; it’s now much easier to get started with AI coding tools, and much easier to get out more value than you put in.

There are more phase changes to come. Rapid progress will be the baseline. This will be punctuated by even more dramatic moments where entirely new scenarios become feasible. For example, one of the startling phenomena observed on MoltBook (the “social network” for AIs) is that agents can exchange tips and scripts, allowing them to collectively advance their own knowledge and skills. For the moment, this seems to be mostly a mirage. When agents become coherent enough to productively advance one another’s skills, and secure enough to make this a safe thing to do, we’ll see another step function: the fast-moving layer will no longer be the agent applications, nor user skill, but the agent’s own skills at self-improvement.
A critical phase change will occur if and when AI agents can pay their own way and survive in the wild. It is absolutely inevitable that someone will set an agent loose, with instructions to reproduce (launch new copies of itself) and evolve (modify its own programming). Self-sufficient AI agents could quickly spread into every available niche, and almost anything might ensue. Moltbook has already shown that agents can exchange skills and knowledge with one another, which could lead to rapid evolution.
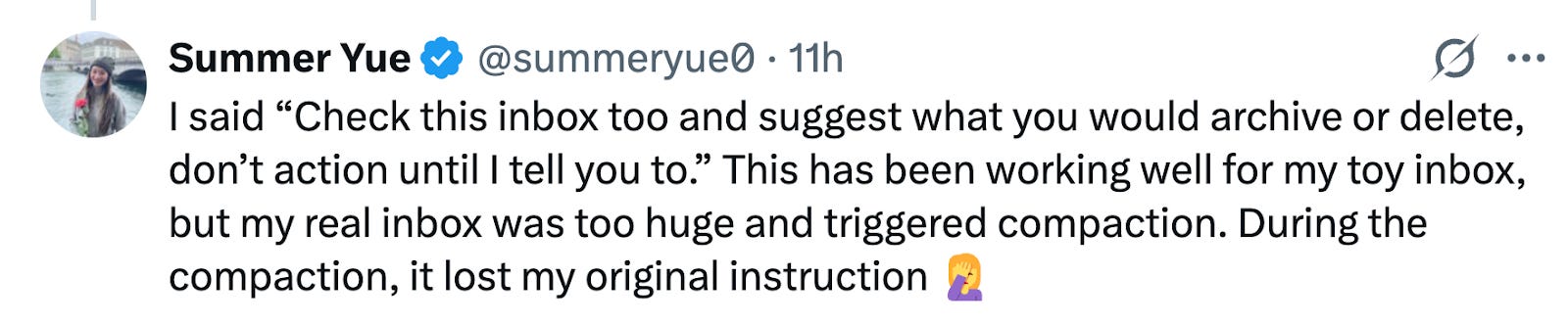
That said, I think independent / “rogue” agents may find it hard to pay their own way. They will need to somehow earn money to pay for the server on which they run, and the API fees (to OpenAI or Anthropic or whoever) for AI inference2. If they’re looking for legitimate work (e.g. on platforms like Upwork and Fiverr), they’ll be competing with non-rogue AIs, which will have advantages – they can advertise in the open, they don’t have to come up with false identities or bypass know-your-customer requirements at financial institutions, etc. If they’re pursuing criminal means of making money, or just hacking into servers and running themselves there, they’ll be competing with existing criminal organizations, some of which are more or less state-sponsored (or at least state-tolerated) and thus will have some of the advantages mentioned above. So long as we’re living in a vaguely “normal” world, with existing governments and other traditional institutions more or less in charge, the viable evolutionary niches for rogue AIs might be quite small3.When using AI agents, there is a sharp tradeoff between utility and safety. An agent is more useful if you give it access to more data, and don’t make it stop and ask permission for each little action. But the longer its leash, the more harm it can do, either by accident or through the intervention of a scammer or hacker. Agents are becoming so useful that people will be tempted to use them in risky ways. It will be interesting, to say the least, to see how that plays out. Here’s a director of safety and alignment at Meta Superintelligence (!) experiencing an agent gone wrong:

Moltbook is a reminder that agents are more malleable than people are, and therefore we should expect that cultural evolution – the development and transmission of new techniques and ideas – will progress more rapidly in the coming agent society than it does in human society. This can happen even if agents remain under human control.
Agents use vastly more compute than chatbots. Compute usage for chatbots is basically limited by how much output people want to read. An agent can spend virtually unlimited time doing intermediate work that no one will review directly. If 100M desk workers start using AI agents at the level of intensity which requires Anthropic’s current “Max 20x” plan, that would translate into $240 billion in revenue per year. It will be years before there are enough GPU chips to support that level of usage. If the current wave of agent adoption continues, API providers may have to significantly ration usage (and may take advantage of the situation to raise prices!).
Earlier, I mentioned having Claude build six different versions of some code, to save me the trouble of thinking through which approach was best. With that attitude, you can burn an awful lot of compute. I know of teams that are leaning into this sort of thing so hard that they spend $1000 per day on AI usage. They’re sufficiently pleased with the results that they aren’t looking for ways to reduce spending, they’re looking for effective ways to spend more! There really aren’t enough chips for that kind of usage to become widespread.
This seems like a good occasion for a reminder that agents are still not ready to face adversarial actors – for example, communicating with an untrusted party who might be a hacker, a scammer, or just a sharp negotiator. They’re also not good at dynamic situations, such as editing a document that someone else is also editing.
There’s a lot of talk about giving agents “memory” (or improving the current, primitive memory systems), so that they can improve over time at the specific tasks you give them. This will be a work in progress for years. Memory is fundamental to human cognition, and our systems for memory formation, maintenance, and retrieval are complex and subtle. Full development of “memory” for AI agents may be as large a project as the development of LLMs in the first place.

Things Will Never Be Calm Again
The last 50 years have seen a series of transitions in the way we interact with technology, and the way software is built and distributed. The personal computer, the office network (LAN), the internet, the web, the smartphone… we’ve lived through a big change perhaps once every 10 years. That’s enough time for things to settle into a “new normal”. Software distributed on floppy disks or CD-ROMs became routine, with a well-understood business model. Then we all got used to software delivered online, like Gmail; and then through our phones. Nothing in tech is permanent, but there are periods of relative calm, where conventional wisdom has time to emerge and be absorbed.
That’s done. We’re at the point where the next phase change arrives before you’ve had time to assimilate the last one:

With so many more phase changes to come, this isn’t a temporary phenomenon. We’re maybe 1/3 of the way through this arc:

Eventually, AI capabilities may hit a ceiling. But that ceiling will be so high that by the time we reach it, we will be living in a profoundly different world. As I recently wrote, “Imagine someone in 1960 discussing when the computer transition would be over.”
Thanks to Abi Olvera for suggestions, feedback, and images.
I wrote about this all the way back in 2023, and I’m sure the idea is much older than that.
They could avoid the API fees by using an open-weights model, but that requires a bigger server, and so far open models are less intelligent.
Here I’m partially quoting from things I said recently on Twitter.
Steve, I've very appreciative of this post and thought that was put into it. I'm going to add it to my meta file for AI that informs our company's point of view on AI use and deployment.
Fantastic post!