
From Compute Overhang to Compute Crunch
The state of AI in Q2 2026, part 2

In the first installment of this “state of AI” series, I reviewed the pace of change. In this installment, I’ll review the factors driving that change. Understanding the forces behind AI progress can help us understand where things will go from here.

A punctured equilibrium
I was in my 20s when the World Wide Web burst onto the scene. I remember being startled at how quickly it went from an obscure technical standard to a household name. On reflection, I realized the web spread rapidly because the ingredients had already been in place. Computers were widespread in the workplace and home. Many were already connected to modems or networks to access AOL, CompuServe, or corporate e-mail. The modems tapped into an existing worldwide network of telephone cables. And there was pent-up demand for services the Web could offer. Like a boulder perched at the edge of a cliff, the world of the 1990s was poised for change.
The AI wave is being driven by another dramatic overhang of untapped potential. Prior to the release of ChatGPT in November 2022:
Semiconductor manufacturing was already an enormous industry, well accustomed to meeting surges in demand.
Close to 100 million “GPU” chips were being manufactured per year. They were primarily used for video game graphics, which involves massive numbers of numerical calculations, meaning these chips could easily be repurposed for training large language models.
Semiconductor factories can easily pivot to new chip designs. As a result, capacity could be shifted from other chips to GPUs, and GPU designs could rapidly be altered to more efficiently execute the “deep learning” algorithms used in LLMs.
Vast quantities of text existed in digital form, ready to be fed into AI training pipelines.
Most non-physical work had long since moved from pen and paper to computers, leaving it poised for automation.
One result is that, since the beginning of 2022, the world’s supply of AI computing capacity has increased by a factor of 1000!
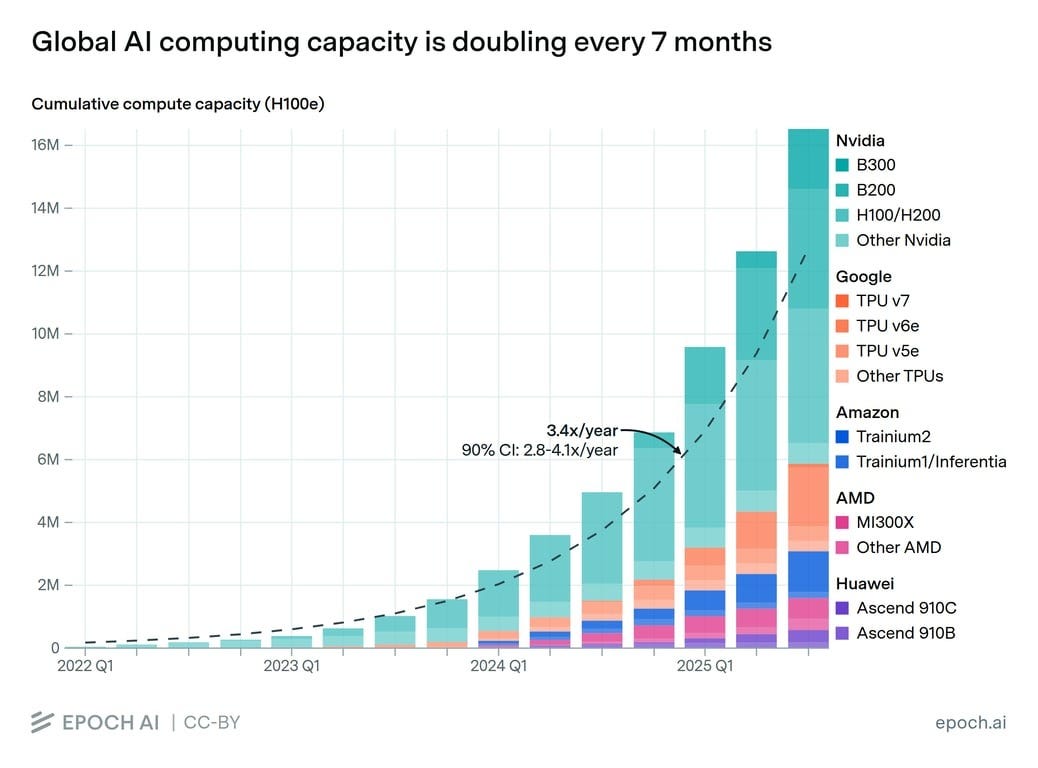
Eventually, some of these tailwinds will peter out, as I’ll discuss below. But for now, all of this untapped potential is driving an insane pace of change. Everyone in the AI industry feels like they’re in a race. Some are racing to beat the competition; some are just racing to rake in money as quickly as possible. The most pivotal race is that between OpenAI and Anthropic.
Two companies are setting the pace – and choosing the course
An unfathomable number of companies are working to develop and deploy AI. Among startups alone, hundreds have raised $100M or more, including many I’ve never heard of.

Despite all this activity, most current action is being driven by progress in two areas:
General-purpose models like ChatGPT and Claude, that are trained on a vast array of data and can take on a wide range of bite-sized tasks.
“Agent harnesses” like Codex and Claude Code, that tackle large projects by breaking them up into a series of tasks that can be handled by a model.
Models, on their own, can do things like answering questions or summarizing documents. Incorporated into an agent harness, they can carry out an increasing range of valuable tasks, from writing software to preparing presentations. Together, they are central to the present-day impacts and expansive future scenarios of AI.
Developing a cutting-edge model is now a multi-billion-dollar proposition. Only five companies have been able to spend that kind of money, and three of them are not getting success for their money.
AI efforts at Meta (Facebook) have been plagued by dysfunction and leadership churn. Meta has never managed to produce a cutting-edge general-purpose model, and at this point, there’s no obvious reason to believe they will. They’ve pushed the state of the art in some areas, and their AI efforts have apparently paid off by improving ad targeting, but they’re not a central player in the most important race.
xAI – Elon Musk’s AI company, now part of SpaceX – has built a pair of gigantic data centers in record time, aptly dubbed Colossus 1 and 2. However, their “Grok” model is best known for contradicting crazy things said by Musk, creating racy pictures of nonconsenting women, and briefly referring to itself as MechaHitler. xAI could conceivably have a future in robotics (a focus for another Musk company, Tesla). But for now, they are such an unimportant player in the AI world (experiencing ongoing departures of key staff) that they can’t make use of the Colossus 1 data center and are handing it to Anthropic.
The most surprising failure, of course, is Google. In a familiar story in tech, Google invented the key technologies behind modern AI, but was caught entirely by surprise when OpenAI commercialized them in ChatGPT. Google has subsequently funneled massive efforts into developing their Gemini model, and while they’ve had much better results than Meta or xAI, they don’t seem to be able to keep pace with the front-runners1. This was brought home by a recent informal survey of preferred AI coding tools, where fewer than one percent of respondents preferred Gemini2:
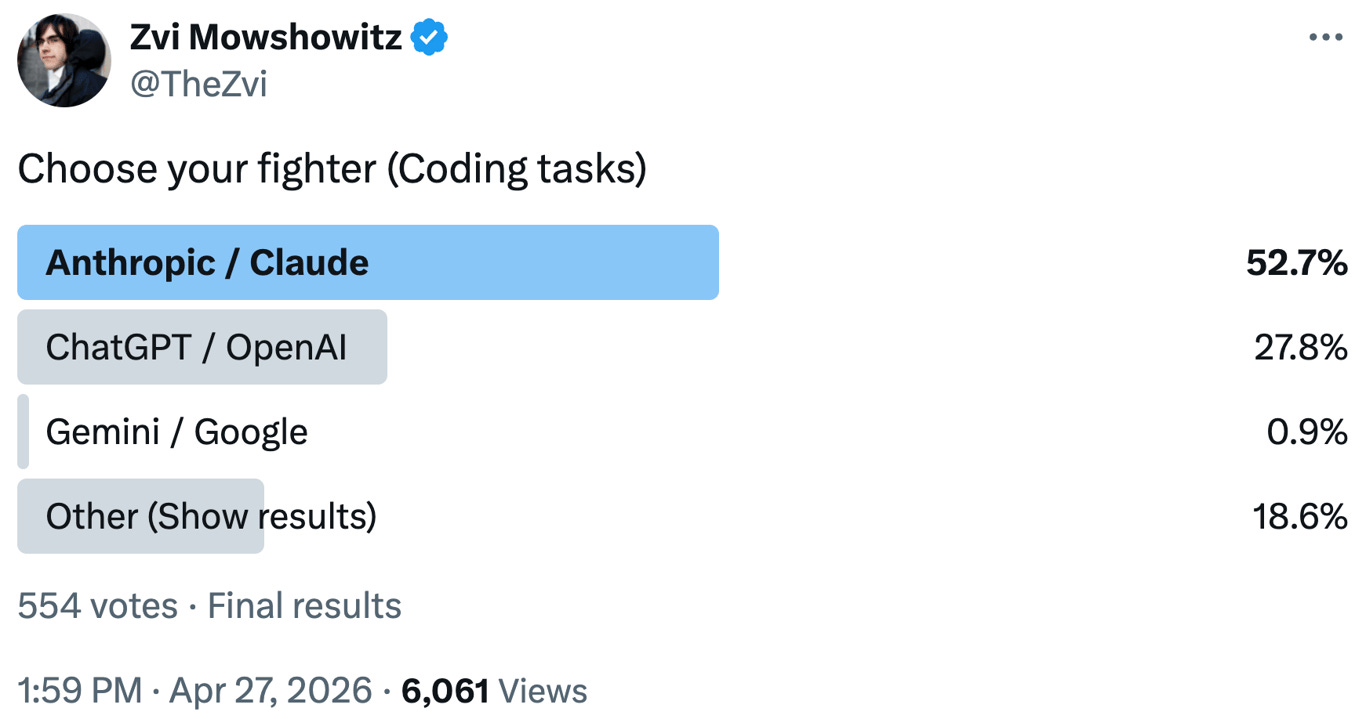
Even more compelling is a fact that I mentioned in my last post: engineers at Google DeepMind prefer Claude over Google’s own tools – to the point where “several engineers reportedly threatened to leave“ if forced to switch.
It would be unwise to count Google out. They have the mother of all cash cows, almost as much AI chip capacity as Microsoft and Amazon combined, a deep bench of AI talent, access to stupendous amounts of data, and distribution via the likes of Google Search, Chrome, YouTube, Android, Gmail, and Docs. But if established companies are good at one thing, it’s squandering opportunities, and in this regard Google has clearly joined the establishment. Their broad portfolio of established products has seemed more of an entanglement than a leg up.
That leaves two companies defining the course of AI.
OpenAI vs. Anthropic: too close to call
From the day ChatGPT took the world by storm, the AI race has been OpenAI’s to lose. And last fall, they appeared to be doing just that – losing. During three years of mostly-unchallenged leadership, OpenAI lacked focus, with plans ranging from videos to wearable devices to advertising to shopping agents, even an ill-fated social network. Meanwhile, Anthropic was moving from strength to strength: the Claude chatbot became the cognoscenti’s tool of choice, Claude Code defined the era of coding agents, and the raw capability of Anthropic’s AI models was advancing rapidly while OpenAI seemed to stumble. In late 2025 and early 2026, there was near-consensus among insiders that Anthropic had pulled ahead in the areas that mattered, while avoiding the controversies and distractions that plagued OpenAI.
Coding agents may be the single most important technology of the moment, as both an enormous moneymaker (strongly contributing to Anthropic’s meteoric revenue), and the tool that is driving the acceleration of AI R&D. And in this area, Anthropic’s lead was especially strong, with Claude Code the almost-undisputed leader. The announcement of Claude Mythos seemed to cement that lead; not only was Mythos astonishingly capable at finding cybersecurity bugs, it smashed records on software development benchmarks.
However, OpenAI – unlike Google – always managed to stay within striking distance. And in the last couple of months, the race is looking more even. OpenAI’s latest model, GPT-5.5, is widely held to be on a par with Anthropic’s current Opus 4.7. They’ve rolled out a flurry of improvements to Codex (their coding agent), narrowing the feature gap with Claude Code. Many insiders are shifting back to OpenAI tools for coding, research, and other “objective” tasks, even if Claude remains the favorite for brainstorming and writing. And OpenAI may still have gas in the tank. There is speculation that GPT-5.5 was rushed out the door without much polish, leaving room for a quick 5.6 followup that could put them in the lead.
Meanwhile, Anthropic is showing signs of strain. Service outages occur shockingly often3. Flubbed attempts to free up computing capacity have caused Claude Code to get accidentally “dumber” on at least three separate occasions, one of which was not fixed for over a month.
This level of service disruption would be inconceivable at most companies

It seems impossible to guess whether either competitor will pull ahead. The best guess might be that OpenAI and Anthropic will continue to play tag – and that their competitors will have a very hard time catching up.
OpenAI and Anthropic are benefiting from feedback loops that have nothing to do with AI automating R&D
Aggressive forecasts for AI progress usually involve a feedback loop where one or more leaders gain an insurmountable advantage. The story goes that whoever has the best AI will use it to accelerate their own R&D, leaving competitors to fall further and further behind. This process is referred to as “recursive self-improvement”, or RSI.
OpenAI and and Anthropic have been consistently out-executing the rest of the AI world for several years now. But AI tools weren’t capable enough to dramatically impact overall R&D progress until recently, so this isn’t RSI in action. Our two front-runners are simply following a pattern that has played out many times in tech – a special mojo that comes with being the leader in an exciting new domain. It starts with early success, based on a strong founding team and culture, a well-positioned product, and luck. That early success builds confidence and attracts investment, customers, and talented staff. There are plenty of ways this can go wrong, but also many examples of it going very right for a long time.
Now, on top of that, 2026 seems to be the year where AI is indeed starting to accelerate its own development. I’ve already mentioned that Google engineers feel hampered if they’re not allowed to use Claude Code. But only Anthropic’s engineers can use their best model, Mythos – it’s not yet available to others (except for cybersecurity purposes). The two front-runners in the AI race, who were already out-executing the rest of the field, will now have the added advantage of early access to the latest and greatest AI coding agents. (Or rather, we’re entering an era where that advantage may become very important.)
The observant reader may notice that I haven’t mentioned China
China sports a rich ecosystem of AI model developers. DeepSeek is the best known, but many companies are doing serious work, including startups like Moonshot AI and tech giants like Alibaba.
I haven’t mentioned any of them, because they’re simply too far behind to play a central role. Conventional wisdom is that Chinese models lag three to six months behind. In reality, the gap is somewhat larger; comparisons are mostly based on benchmark scores, and Chinese models tend to score better on benchmarks than in real-world usage. Furthermore, they appear to be substantially drafting off of frontier US models, whether by using US models to generate training data, or simply focusing effort on areas where US models have been observed to succeed. If OpenAI and Anthropic were to slow down, progress in China might slow as well.
A lag of 8 months or so may not sound like much, but in the world of AI it’s enough to render a product uncompetitive. Chinese AI developers have not captured a large share of the market – even domestic companies often use US models, and they may struggle to sustain the ever-increasing levels of investment required to stay in the game (though DeepSeek is giving it a shot). Indeed, they may now be falling further behind.
Another popular story is that China’s scrappy AI startups, lacking the enormous resources being invested in the US, have developed more efficient techniques. This appears to be an exaggeration: the major American labs have also been aggressively pursuing efficiency, driving down the cost for a given level of AI capability by 10x per year. There are instances of Chinese companies offering AI services at a steep discount to US pricing, but these services don’t seem to be capturing much market share4.
None of this is to denigrate the capability of Chinese AI researchers. Teams like DeepSeek are doing top-notch work, but they’re hampered by lack of access to American chips and financial markets. In the world of AI, it is abundantly clear that size matters.
Chinese companies do play an important role in supporting academic AI research, including American research. That’s because they often release their model “weights” – the data file that makes up the actual AI model – for anyone to use. This allows researchers (and startups) around the world to study and modify those models. They also publish papers describing many of their advances, something that has become quite rare at leading US labs who now focus on preserving competitive advantage.
Much of China’s AI effort is focused on an entirely different domain: robots, factory automation, driving, and other “embodied applications”. These will be huge markets, but are not currently central to the great AI race.
Chinese “open-weight” models play a leading role in important niches, such as small AI models that can run locally on a smartphone, drone, or other “edge device”. But so long as the US retains its dominant position in the build-out of AI data centers, Chinese models seem likely to remain stuck in these niches.
And speaking of data centers, that leads me to my last topic...
The great compute crunch
Earlier, I presented a graph showing that installed AI computing capacity is doubling every 7 months. Overall AI capacity is growing even faster, as developers from OpenAI to DeepSeek find “algorithmic improvements” – ever-more-efficient ways to turn computing power into intelligence.
It’s not enough. Demand has been increasing faster than supply, and AI providers – especially Anthropic – are starting to tighten usage limits or move from flat rate to usage-based pricing. (Sam Altman’s aggressive past pursuit of data center deals may now give OpenAI an important advantage5, locking in plenty of capacity for the next few years.)
This is driven by the explosion in use of AI “agents”. A single prompt to an agent can result in the AI working for minutes or hours. Software engineers often have many agents grinding away at once, and can easily use more tokens in one day than a casual ChatGPT user might consume in a year.
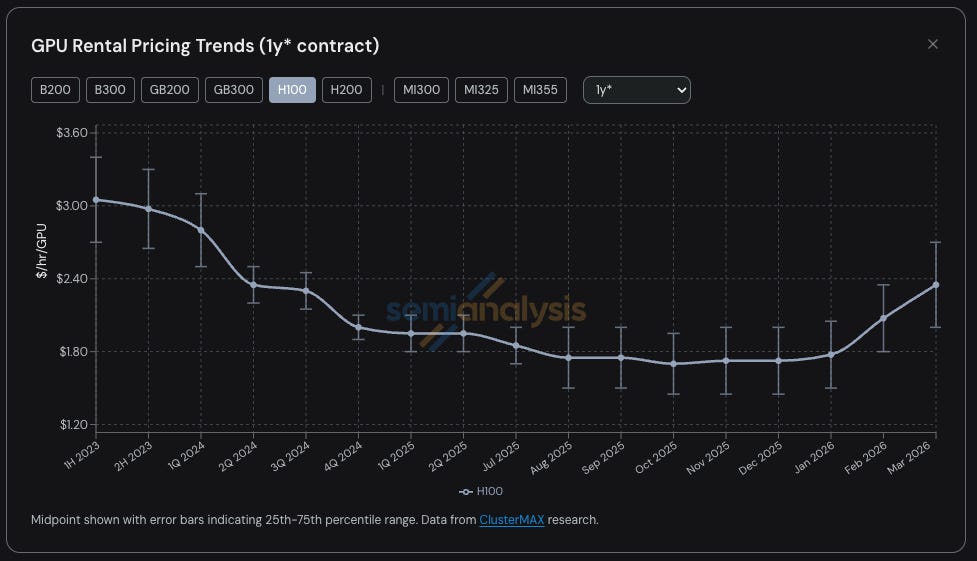
Until very recently, the conventional wisdom was that GPU chips would have a useful lifetime of 3 to 5 years, after which they’d be replaced by new, more efficient chips. In actuality, rental prices for four-year-old H100 chips, which had been falling over time, have recently begun to soar, because there’s enough demand to saturate all available chips – old and new.
The crunch may get worse. Conventional wisdom is that by 2030, AI will be using most of the world’s advanced semiconductor manufacturing, at which point it will become impossible to maintain the current rate of growth in computing capacity. And other bottlenecks might arrive sooner; one respected analyst forecasts that AI will use a majority of all memory (DRAM) manufacturing capacity this year, and 69% next year! The resulting memory shortage is already causing price hikes for laptops and cell phones. So the world is running out of capacity to shift production away from other chips toward AI.
As a result, the brief era of universal access to cutting-edge AI is ending. Andy Warhol famously noted that Coca-Cola is egalitarian: “the President drinks Coke, Liz Taylor drinks Coke, and ... you can drink Coke, too”. For the first few years after ChatGPT launched, something similar was true for AI – top-notch capabilities were mostly available for free or, at most, $20 / month. With the introduction of agents, that’s no longer sustainable. I’m paying $200 / month to Anthropic to support my Claude Code habit, and another $200 / month to OpenAI for access to their “Pro” research agent. A year from now, if trends hold, those capabilities will be available for $20 / month... but my spending will probably have increased, because I’ll want access to the latest and greatest capabilities6. Meanwhile, some “tokenmaxxing” engineers already spend hundreds of dollars per day to operate fleets of coding agents. Individuals and companies who can’t afford these prices may struggle to compete.
The compute crunch may also slow progress in AI capabilities. It will not, however, stop it: new chip fabs are being built, and algorithmic improvements keep squeezing more value out of each chip.
The shortage of GPUs brings me back to China. China’s AI efforts are drastically limited by export controls on GPU chips and other specialized equipment. We’ve already discussed how this prevents Chinese labs from training cutting-edge models. It also greatly limits the country’s ability to use AI, even once it’s been trained: there are simply not enough data centers in China to support anything like the intensity of usage that is emerging in the US and some other countries.
(If AI demand continues on its current trajectory, access to computing capacity may soon become an issue for every country, with GPUs the “new oil” and the US a one-country cartel7.)
For years, China has been working to reduce its dependence on chip imports. The country now has a substantial semiconductor manufacturing industry. However, it primarily produces lower-complexity chips, such as those used in automobiles. Its ability to produce advanced chips such as GPUs is highly constrained, depending on imported manufacturing equipment which is also subject to export controls. Many of China’s AI data centers are populated with smuggled chips.
Jensen Huang, CEO of Nvidia (the leading maker of GPU chips for AI), argues that export controls will simply encourage China to develop its own chip industry. However, this appears to be out of touch with reality. It seems clear that China will continue racing to expand domestic chip production whether or not the US maintains export controls. The country has been aggressively pursuing that path for years, forbidding Chinese companies from using imported chips whenever domestic alternatives are available – even when those alternatives are inferior.
The forces driving AI progress
To understand where AI is heading, it helps to understand the forces that are driving progress. As we’ve seen, the impact of AI is centered on “agents” and the general-purpose models they rely on. Progress so far has been driven by two key factors. The first is an overhang of potential that was ready to be tapped by AI:
Chip manufacturing capacity (being rapidly repurposed to manufacture GPU chips)
Digital data (that those chips can process to train AI models)
Electronic work (that is ready for automation)
The second is a positive feedback loop at OpenAI and Anthropic: their success draws investment, customers, and talent, fueling further success.
The overhang effect may peter out over the next few years. During that same period, AI itself may pick up the slack via the aforementioned recursive self-improvement: helping to design more-efficient chips, generating its own training data, and accelerating the work done by researchers and engineers at the AI labs.
As AI agents become able to work unattended for longer periods, demand for computing power is outstripping supply. This is leading to a world of AI haves and have-nots: those with money will have access to smarter agents and be able to use them for more tasks. At the international level, China will be at a major disadvantage, so long as export controls remain in place and effective8.
This picture seems likely to hold for at least the next few years, until one of the following things happens:
Robots start to broadly automate physical labor. This could pull the center of gravity away from agents, OpenAI and Anthropic. It might also shift the advantage to China, with its vast industrial base and commanding lead in manufacturing motors, batteries, and other robot components.
Automation of AI research leading to a true intelligence explosion, with unpredictable consequences.
An x-factor, such as popular distrust of AI in the US leading to a serious data center ban, or geopolitical strife impacting Taiwanese semiconductor manufacturing.
It’s possible that some startup will emerge with a new approach to AI that allows it to blow past OpenAI and Anthropic. But it’s at least as likely that the current leaders would manage to incorporate the new idea. It’s also possible that AI revenue growth will slow enough to break the feedback loop of success. But despite concerns at OpenAI, I think this is unlikely. Things might slow down; one of the leaders might stumble. But OpenAI and Anthropic have enough momentum that I expect at least one of them to remain in the lead for at least the next few years. And, barring a serious recession (and perhaps even then), I expect advances in AI capability to continue indefinitely. There are too many competitors in the race, and too many factors driving it forward, to expect any other outcome.
This is the second installment of my “state of AI” series. The first installment discussed the pace of change. In the remaining installments, I’ll cover impact (both positive and negative), the politics of AI, and how to personally navigate the coming era.
Lots of people provided suggestions and feedback for this series! Thanks to Abi Olvera, Alex Booker, Clara Collier, Dave Kasten, Eli Pariser, Emma Kumleben, Gideon Lichfield, Kai Williams, Taren Stinebrickner-Kauffman, and Tim Schnabel. Apologies if I missed anyone!
Google’s annual conference will take place around the time I publish this, and there are reports that they’ll announce a new Gemini model but that it “won’t be pushing the frontier”. Meanwhile, Google’s struggles on the product front may be even greater than on raw model capabilities, and this is a challenge that a sprawling organization seems ill-equipped to overcome.
This audience may be biased toward Anthropic, so don’t take the Claude / ChatGPT mismatch too seriously.
This link leads to Anthropic’s live status page; the statistics shown there will almost certainly improve at some point. The image in this post shows how things looked as I was drafting this post.
I’m not entirely sure what is going on here. Certainly Chinese providers have capacity limits, but if a model truly delivers competitive price / performance, you’d expect some arrangement to run it on data centers in other countries, especially since most of these models are open for anyone to run. It could be that the real-world performance of these models is simply not good enough to be attractive for most customers even at a low price. There may be bias against Chinese models. Or it could be a simple lack of awareness.
One recent estimate shows OpenAI having contracted twice as much future data center capacity as Anthropic.
As Anton Leicht explains:
The often-invoked hope that ‘efficiency curves’ will compress token costs quickly doesn’t save us here: efficiency curves mean that next year, Mythos-level capabilities might be very cheap; they don’t mean that Mythos 2 will be cheaper than Mythos. The opposite is the case: frontier capabilities have grown more expensive month-to-month for years now.
Taiwan, not the US, holds the overwhelming majority of advanced semiconductor manufacturing facilities. And other countries, such as Japan, dominate supply of other critical components for AI data centers. However, to date, these countries have allowed the US to play the dominant role in determining where that supply goes.
Or until their domestic industry catches up, but this will take many years.
this piece gives me so much clarity on the ai trajectory, thanks for writing it steve!
Good essay, looking forward to future ones. Three objections to your argument here — curious for your thoughts.
1/ on RSI — you suggest this may be happening, but what leads you to believe this? Section 9.1.3 of GPT 5.5’s system card is remarkably candid that they’re seeing effectively none of this — which is a striking admission if part of their valuation is premised on the inevitability of takeoff. Ie “Trust me, we have to run in the red because we have to get to RSI first!”
2/ on China — you don’t cover the price and margin compression dynamics that open source which is “good enough” create for frontier labs. If I can get sonnet-level performance out of deepseek v4 for pennies on the dollar per 1M output tokens compared to frontier labs, why would I pay extra if all I really need is sonnet-level performance? Good enough is good enough, for what I expect will be the vast majority of consumer and enterprise workloads (basic text summarization and retrieval stuff). There are really diminishing marginal returns to frontier performance unless you believe they’re getting closer to takeoff. China’s play (IMO the smart one) is to just structurally undercut US frontier lab margins, ushering in the next winter and then claiming dominance. But they don’t believe in AGI, so that’s not their goal.
3/ On rates of improvement — a lot of this seems premised on either 1 or 2 not being a structurally-persistent issue. But even if continued linear improvement WERE possible, giving diminishing marginal returns, why would investors front the capital required to fund increasingly-less profitable training runs? Even if there’s more low-hanging fruit to pluck, why should we assume there will be private appetite to pluck it?
Finally — as someone who has led private companies I’m sure you’re familiar with the importance of messaging discipline in the road to IPO or acquisition. So wouldn’t you agree that it’s a little suspicious for both OpenAI and Anthropic to publicly claim they’ll void any insider share selling in forward contracts or SPVs? Like, what’re they so afraid of here? Why feel compelled to make this announcement at all? Unless insiders and their creditors systematically believe these companies are overvalued and see the unit economics writing on the wall. OpenAI is trading at a discount in secondary markets already and MSFT is almost certainly going to programmatically trim their ~30% stake. How does all this not spell trouble?